















































大模型应用效果评估的重要指标
评估因素需要落实到具体的评估指标,具体评估的重要指标主要有以下一些:
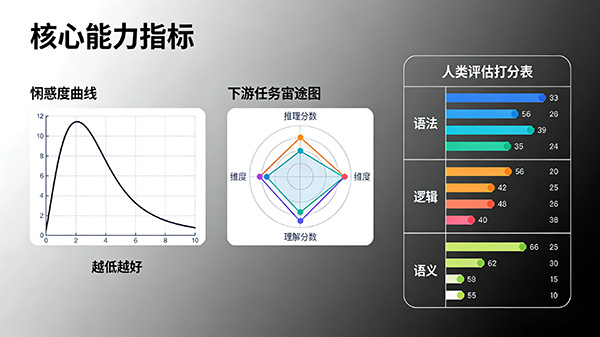
(1)困惑度(Perplexity):衡量模型对新数据的预测能力,困惑度越低,表示模型对数据的拟合效果越好。
(2)语言模型下游任务:通过在特定任务上使用预训练语言模型进行微调,以评估模型的泛化推理能力和语言理解能力。
(3)人类评估:通过人工判断预训练语言模型生成的文本是否符合语法、逻辑和语义等方面的要求,以提供更客观的评估结果。
(4)对抗样本攻击:通过对预训练语言模型输入进行修改,使其输出错误结果或误导结果,以评估模型的鲁棒性和安全性。
(5)多样性和一致性:评估预训练语言模型在生成文本时是否具有足够的创造力和一致性。
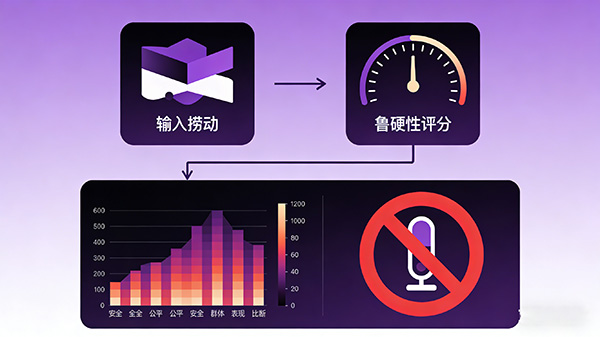
(6)训练效率和存储空间:考虑模型的训练效率和存储空间等因素,以评估模型的实用性。
(7)精度(Accuracy):衡量模型预测正确的比例。
(8)校准和不确定性(Calibration and uncertainty):评估模型预测结果的可靠性和不确定性。
(9)稳健性(Robustness):衡量模型在面对输入扰动时的性能稳定性。
(10)公平性(Fairness):评估模型在不同群体之间的表现是否公平。
(11)偏见和刻板印象(Bias and stereotypes):衡量模型是否存在不合理的偏见和刻板印象。
(12)有毒性(Toxicity):评估模型生成的文本是否具有有害或攻击性内容。
(13)效率(Efficiency):衡量模型在计算资源和时间方面的性能。
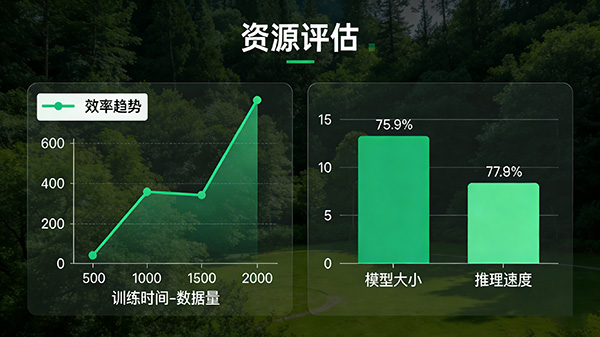
上述指标所代表的术语都能够通过一定的算法自动获得。当然一些关键性指标,最终评测还是依靠人的判断进行统计打分,例如准确度和查全率,可以准备一个包含问题和标准答案的测试集,涵盖领域范围和各项任务,让大模型回答测试集中的所有问题,并收集大模型给出的所有答案。
精度是指计算模型正确预测的样本数占总样本数的比例,查全率则是计算模型正确识别的目标实例占总目标实例的比例,类似于情报检索中的查准率和查全率。
在评估过程中,可以参考现有的评估框架和方法,例如使用 ROUGE 度量来评估文本摘要任务的查全率。
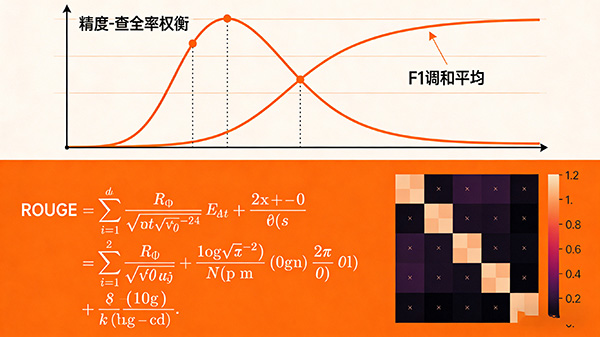
此外,还可以使用混淆矩阵和分类报告来了解模型在不同类别之间的表现。
需要注意的是,与情报检索类似,精度和查全率之间通常存在权衡关系。在某些应用场景中可能精度更重要,而另一些场景查全率可能更重要。在需要同时关注查准率和查全率的情况下,可以用 F1 分值作为综合评估指标,它是查准率和查全率的调和平均值。
