















































语音识别技术如何提高识别准确率?
2026-05-31 09:09:00阅读 7540

语音识别技术可以通过以下几种方法提高识别准确率:
1.预处理:在语音识别之前,对输入的音频信号进行预处理,如降噪、滤波、标准化等操作,可以提高语音识别的准确性。

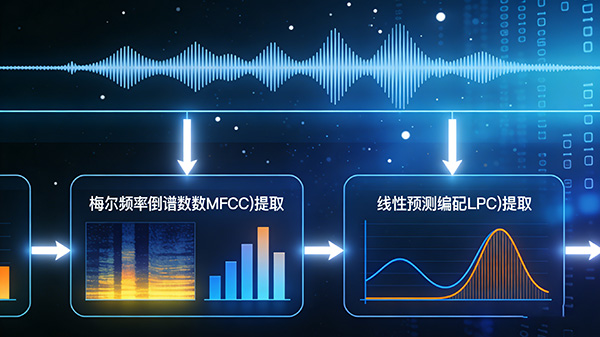
2.特征提取:在语音信号中提取出与语音相关的特征,如梅尔频率倒谱系数(MFCC)、线性预测编码(LPC)等,这些特征可以更准确地表示语音信号,从而提高识别准确率。
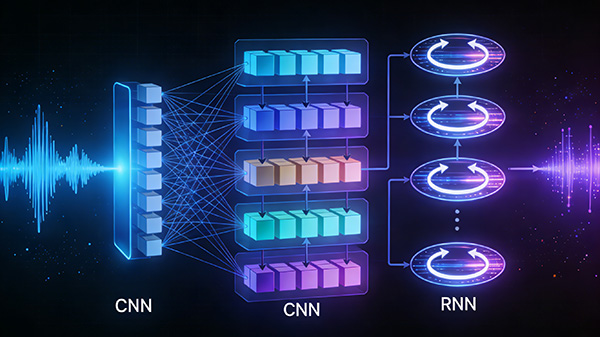
3.深度学习:采用深度学习算法对语音信号进行建模,如卷积神经网络(CNN)、循环神经网络(RNN)等,这些模型可以自动学习语音特征,并提高识别准确率。
4.训练数据:增加训练数据可以提高语音识别准确率。通过收集更多的语音样本,可以训练出更精确的语音识别模型。
5.语言模型:语言模型可以预测文本序列的可能性,从而降低语音识别的错误率。通过训练语言模型,可以进一步提高语音识别准确率。
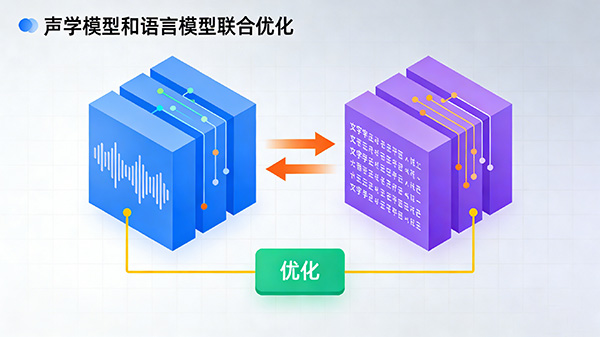
6.声学模型和语言模型的联合优化:声学模型和语言模型是语音识别的两个关键组成部分。通过对这两个模型进行联合优化,可以提高识别准确率和鲁棒性。
7.语音增强:通过语音增强技术,如自适应噪声消除、回声消除等,可以提高语音质量,从而提高识别准确率。
8.口语规范:对于非标准或随意的口语表达,可以通过口语规范技术将其转化为标准表达,从而提高识别准确率。
9.多通道识别:利用多个麦克风同时进行语音录制,可以获得更好的音频信号和更高的识别准确率。
10.持续学习:通过持续学习技术,可以对新的语音数据进行训练,从而不断提高语音识别准确率。
总之,语音识别技术可以通过多种方法提高识别准确率,包括预处理、特征提取、深度学习、训练数据、语言模型、声学模型和语言模型的联合优化、语音增强、口语规范、多通道识别以及持续学习等。这些方法可以根据不同的应用场景和需求进行选择和组合,以实现最佳的语音识别效果。
