















































生成式和判别式模型的区别
生成式模型和判别式模型在机器学习领域中都是重要的模型类型,但它们之间存在着一些显著的区别。本文将从定义、原理、应用场景和优缺点等方面对这两种模型进行详细的比较。
一、基本概念
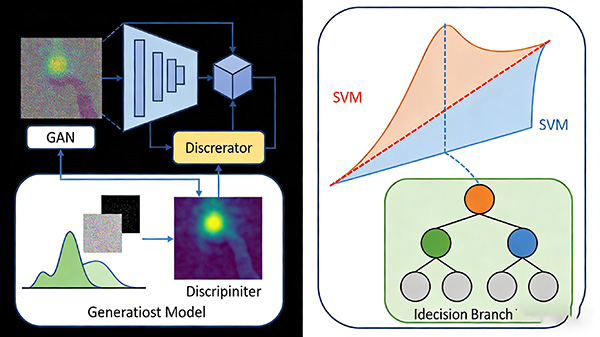
生成式模型:通过学习数据分布来生成样本,通常用于模拟生成新的数据。例如,生成对抗网络(GAN)就是一种常见的生成式模型。
判别式模型:通过学习输入变量和目标变量之间的概率分布来进行预测或分类。例如,支持向量机(SVM)、朴素贝叶斯和决策树等都是判别式模型。
二、原理
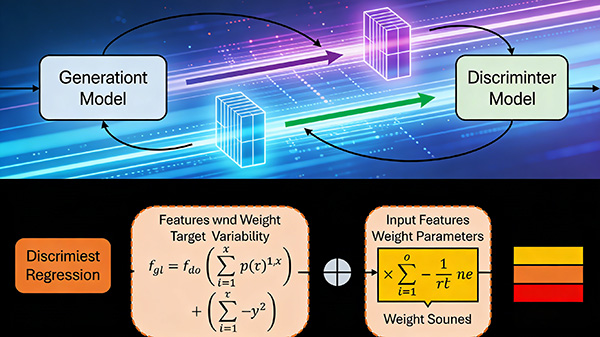
生成式模型:通过深度学习技术,学习数据分布,生成与原始数据类似的新样本。它主要关注的是生成数据,而非预测或分类。例如,GAN通过两个神经网络相互竞争,不断优化生成假样本的能力。
判别式模型:通过学习输入变量和目标变量之间的关系,对未知数据进行分类或预测。它关注的是如何最大化分类的准确性或最小化预测的误差。例如,逻辑回归模型根据输入特征和权重,计算出目标变量的概率。
三、应用场景
生成式模型:常用于图像、音频和视频生成,以及模拟复杂的自然现象等。例如,GAN可以生成逼真的图像,而变分自编码器(VAE)可以生成音频样本。
判别式模型:广泛应用于分类、回归和异常检测等任务。例如,SVM可以用于分类问题,而线性回归可以用于预测房价等实际问题。
四、优缺点
生成式模型:
优点:具有强大的生成能力,可以模拟复杂的自然现象并生成新的数据样本;在创意设计等领域具有广泛的应用前景。
缺点:训练难度较大,容易陷入局部最优;生成的样本可能存在一定的偏差或模式崩溃的风险。
判别式模型:
优点:适用于分类和回归等常见机器学习任务,具有较高的分类准确率;训练相对稳定,收敛速度较快。
缺点:对于处理高维复杂数据时可能存在过拟合问题;无法像生成式模型那样生成全新的样本。

五、结论
生成式模型和判别式模型在机器学习领域各具特色,应根据具体任务需求选择合适的模型类型。
生成式模型在创意设计、数据增强等领域具有广泛的应用前景,而判别式模型则在分类、回归等常见任务中表现出良好的性能。
未来,随着深度学习技术的不断发展,这两种模型将会进一步融合,并在更多领域发挥重要作用。
