NLP中常用的文本分类模型
在NLP领域,文本分类是一项基础且重要的任务。
以下我将为你介绍几种常用的文本分类模型:
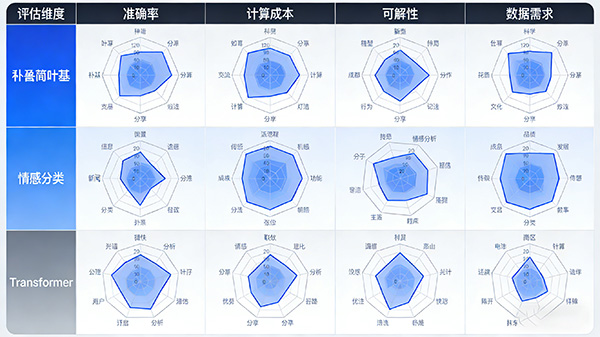
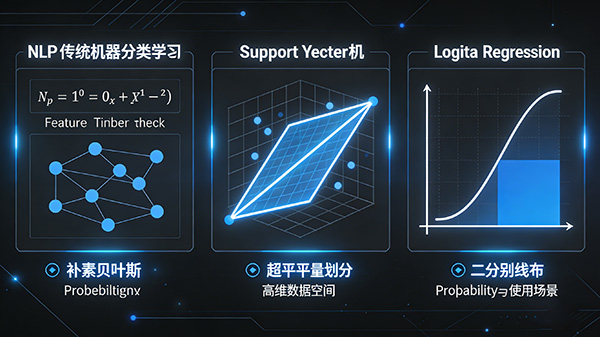
1. 朴素贝叶斯分类器(Naive Bayes Classifier)
原理:基于贝叶斯定理与特征条件独立假设的分类方法。
它假设一个特征在给定输出的情况下与另一个特征无关。
特点:简单高效,对于大规模数据集表现良好,但假设条件可能过于简单,不适用于所有情况。
适用场景:新闻分类、垃圾邮件检测等。
2. 支持向量机(Support Vector Machine, SVM)
原理:通过寻找一个超平面来对训练数据进行划分,使得不同类别的数据点分布在超平面的两侧。
特点:对高维数据处理效果好,具有较好的泛化能力,但需要选择合适的核函数和参数。
适用场景:文本分类、情感分析、信息抽取等。
3. 逻辑回归(Logistic Regression)
原理:利用逻辑函数(sigmoid函数)将线性回归的预测值映射到0和1之间,从而得到分类的概率。
特点:计算简单,可解释性强,适用于二分类问题。
对于多分类问题,可以通过多次二分类来实现。
适用场景:垃圾邮件识别、情感分析、推荐系统等。
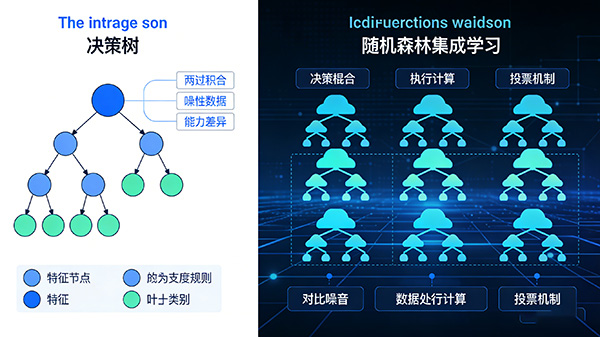
4. 决策树(Decision Tree)
原理:通过一系列规则对数据进行划分,形成树状结构。
每个节点代表一个特征,每个分支代表该特征的一个取值,每个叶子节点代表一个类别。
特点:易于理解和实现,可解释性强。
但容易过拟合,对噪声数据敏感。
适用场景:文本分类、特征选择、规则学习等。
5. 随机森林(Random Forest)
原理:基于决策树的集成学习方法。
通过构建多个决策树,并对它们的预测结果进行投票或平均,以提高分类的准确性和稳定性。
特点:具有良好的泛化能力,能够处理高维数据和噪声数据。
但计算成本较高。
适用场景:文本分类、特征选择、异常检测等。
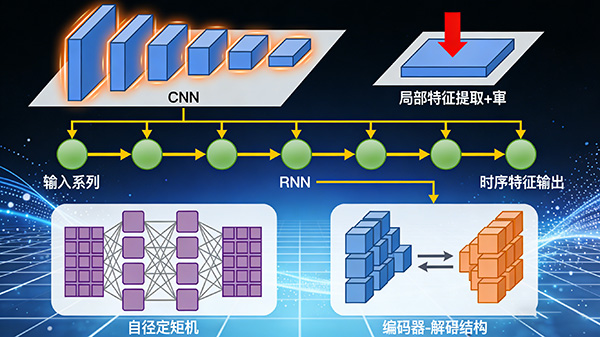
6. 深度学习模型(如卷积神经网络CNN、循环神经网络RNN、Transformer等)
原理:通过模拟人脑神经网络的工作方式,自动学习数据中的特征表示,并进行分类。
特点:能够处理复杂的非线性关系,自动提取特征,对大规模数据表现良好。
但需要大量的计算资源和训练时间。
适用场景:文本分类、情感分析、机器翻译、问答系统等。
这些模型各有优缺点,适用于不同的场景和任务。
在实际应用中,需要根据具体的数据和需求来选择合适的模型。