















































如何自动处理TP返修品清单的SAS系统数据?从清洗到回写
TP返修品清单的SAS系统数据,难点从来不是把表导出来,而是把字段识别、规则校验、异常分流、结果回写、审计留痕做成一条稳定链路。只要返修数据还靠人工下载、筛列、比对、复制、回填,处理周期和差错率就会一起放大;更稳妥的做法,是把SAS报表、Excel附件、邮件通知和ERP或售后系统连成自动闭环。
 图源:AI生成示意图
图源:AI生成示意图
一、先看本质:TP返修品清单为什么总卡在人工环节
这类SAS数据通常不只是一个表
无论TP指代第三方返修、渠道返修还是内部售后分组,只要清单来自SAS报表或SAS导出表,处理对象通常都包含这些字段:
- 基础标识:返修单号、料号或SKU、SN码、批次号
- 过程字段:入库时间、返修状态、仓位、处理人、服务商
- 判定字段:故障现象、责任归属、是否超期、是否重复返修
- 业务结果:退款、换新、补发、报废、二次检测、升级工单
人工处理最容易断在四个位置
- 字段口径漂移:同一字段可能改名、换列、被写入备注,导致脚本和人工模板频繁失效。
- 多源数据不一致:SAS、ERP、WMS、售后邮件和供应商回传表使用的命名不同,人工需要反复对照。
- 规则依赖经验:是否超保、是否重复返修、是否需要升级处理,往往掌握在少数熟练员工手里。
- 结果难追溯:谁修改了状态、为什么退回、哪次回写失败,证据散落在表格、聊天记录和系统日志里。
所以,所谓自动处理,不是简单做一个导出宏,而是把数据理解、规则判断和跨系统动作统一起来。
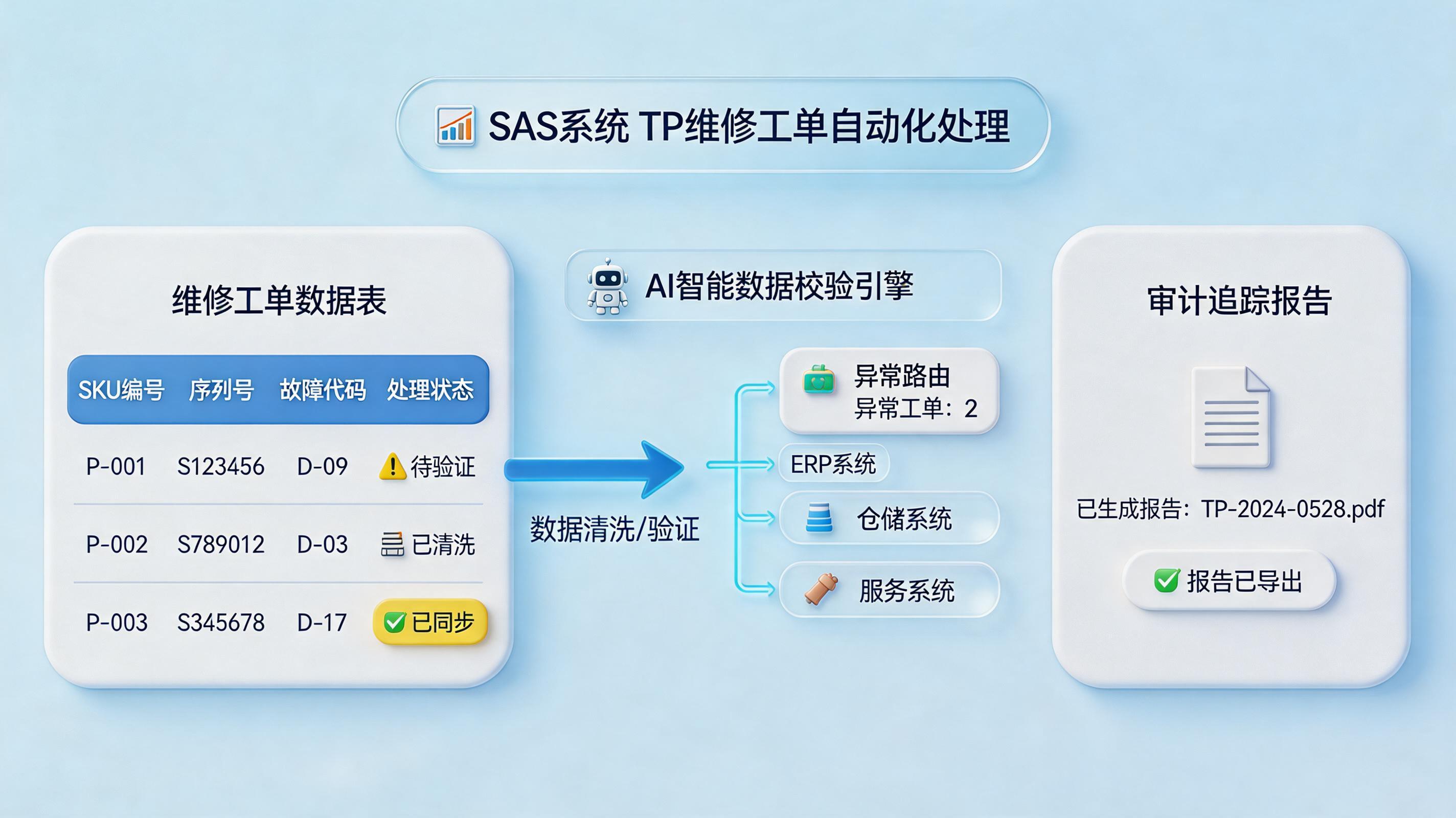
二、真正可落地的方式:把SAS返修数据做成五步闭环
Gartner曾预测,到2026年超过80%的企业将使用生成式AI API、模型或生产级应用;McKinsey在2023年研究中指出,生成式AI每年可为全球经济新增2.6万亿至4.4万亿美元价值。对企业来说,最先兑现价值的,往往不是宏大叙事,而是返修、报销、工单、订单这类高频数据流。
一条可执行的处理链路
- 自动获取:定时抓取SAS导出文件、共享盘表格、邮件附件,或直接监听指定目录。
- 字段标准化:把不同表头映射为统一字段,例如把料号、产品编码、SKU归并为同一主键。
- 规则校验:自动检查空值、重复值、超期件、状态冲突、责任归属异常、SN缺失等问题。
- 异常分流:能自动决策的直接流转;低置信度或冲突数据进入人工复核池。
- 结果回写与留痕:将结果写回ERP、WMS、OA或售后系统,同时生成日志、附件或PDF记录。
SAS导出或邮件附件 → 字段标准化 → 业务规则校验 → 异常分流 → ERP或WMS回写 → 审计日志归档,这才是一条完整的数据处理链。
一个简化后的任务拆解表
| 处理环节 | 输入 | 系统动作 | 输出 |
| 数据抓取 | SAS报表、Excel、CSV、邮件附件 | 自动下载、归档、重命名、版本识别 | 统一待处理数据集 |
| 数据清洗 | 多种表头和备注文本 | 字段映射、空值修补、格式转换、去重 | 标准化清单 |
| 规则判断 | 返修时效、责任规则、状态字典 | 比对主数据、匹配规则引擎、识别异常 | 可执行结果和异常清单 |
| 业务流转 | 标准化结果 | 自动建单、回写状态、发送通知 | 闭环处理结果 |
| 审计追踪 | 全链路日志 | 生成附件、留档、权限隔离 | 可追溯证据链 |
三、不是只靠脚本:TP返修清单自动化需要怎样的技术路径
如果企业希望稳定运行,而不是做一个三天后就失效的脚本,通常需要四层能力协同:
- 接入层:连接SAS导出目录、共享盘、邮箱、ERP、WMS、OA、客服系统。
- 理解层:识别表头别名、备注文本、扫描件和非结构化附件,理解返修规则语义。
- 执行层:跨系统登录、查询、填写、上传、回写、下载,完成真正的业务动作。
- 治理层:权限控制、异常告警、日志留痕、审计追踪、人工复核入口。
实在Agent在这类场景中的价值,不是替代一个表格公式,而是把大模型意图理解、IDP文档识别、RPA跨系统操作、规则引擎校验和审计追踪串成闭环。这样做的好处是,系统既能理解SAS数据里的半结构化信息,也能真正进入业务系统完成回写和通知。
更适合生产环境的实现方式
- 先规则、后智能:对SN格式、超期天数、责任归属等强规则先固化,再让模型处理备注、异常说明和字段歧义。
- 低置信度不强推:识别不清或规则冲突的记录进入人工队列,避免错误自动回写。
- 全链路留痕:每一步记录来源文件、处理时间、动作结果和操作账号,方便售后稽核。
- 支持私有化与权限隔离:返修和售后数据通常涉及订单、客户、库存和财务信息,必须满足企业合规要求。
实在智能在企业自动化实践中,常采用AGI大模型加超自动化全栈技术路径:以大模型负责理解和决策,以CV、NLP、IDP负责识别非结构化内容,以RPA完成跨系统执行,再由审计链路保证每一次处理都可回溯。这种方法比单点脚本更适合返修数据这种高波动场景。
四、哪些场景最适合先做,最近似的客户实践说明了什么
优先自动化的四类返修清单
- 日清或周清批量清单:数据量固定、频率高,人工最容易疲劳出错。
- 跨系统核对清单:需要同时对照SAS、ERP、WMS和售后系统,人工切系统成本高。
- 异常件回溯清单:涉及重复返修、超期、缺件、责任争议,需要系统自动筛出重点。
- 审计要求强的清单:需要保留处理证据、附件、日志和回写记录。
最接近的真实业务迁移路径
在某类跨境业务场景下,数字员工已用于读取邮件订单并自动录入进销存;在另一类共享财务场景中,已实现发票验真、合规检查及ERP录入,并可同步生成PDF附件满足审计追溯。把这两类成熟能力迁移到TP返修品清单处理,底层动作其实一致:读取文件、识别字段、执行规则、跨系统回写、输出日志。因此,SAS返修数据自动化并不需要从零开始建设,完全可以沿用成熟的跨系统自动化框架。数据及案例来源于实在智能内部客户案例库。
上线时建议先做一个小闭环
- 先选一类高频返修清单,例如每天固定导出的TP返修表。
- 梳理最少必要字段,例如单号、SKU、SN、状态、责任归属、结果动作。
- 确定三类规则:强规则、弱规则、必须人工复核规则。
- 先打通一个回写系统,而不是一次接入所有系统。
- 最后再补全消息通知、日志、报表和看板。
这样做的原因很简单:返修数据的难点往往不在技术,而在规则边界。如果边界先清楚,自动化才能持续稳定。
🔎 常见问题
Q1:SAS导出字段经常变化,自动化会不会很快失效?
不会,但前提是方案不能只靠固定列号。更稳妥的方法是建立字段别名库、表头识别规则和低置信度兜底机制。列顺序变了、字段名略有变化时,系统仍能通过语义和样本映射识别目标字段。
Q2:返修备注很多是自然语言,能自动识别吗?
可以。备注、故障现象、责任说明这类文本,适合交给大模型做分类、摘要和标签化处理;但涉及退款、报废、责任归属等关键决策时,仍应叠加规则引擎和人工复核,避免只凭模型直接拍板。
Q3:如果企业很重视数据安全,适合怎么部署?
优先考虑私有化部署、权限隔离、桌面审计和全链路日志。返修清单往往连着订单、库存、客户和财务信息,只有把访问权限、回写动作和审计记录都管起来,自动化才能真正进入生产环境。
参考资料:McKinsey于2023年6月发布《The economic potential of generative AI: The next productivity frontier》;Gartner于2023年发布关于到2026年企业使用生成式AI比例预测的研究观点。上述机构数据用于行业趋势说明,具体项目收益仍取决于企业流程成熟度、数据质量和系统集成范围。



