















































网页数据抓取工具哪个好?RPA自动化实施网页抓取的策略
凌晨三点,某电商公司数据分析部依然灯火通明。团队主管李明盯着屏幕上停滞不前的爬虫程序日志,脸色凝重——竞争对手的新品价格数据又一次抓取失败,反爬机制再次升级,而明早的定价决策会议急需这份数据。与此同时,同城一家金融机构的办公室里,风控经理王芳刚刚收到RPA机器人自动生成的全网舆情风险报告,涵盖数百个来源的最新数据,全程无需人工干预。相同的需求,不同的技术路径,结果天差地别。在数据驱动的商业时代,选择正确的抓取工具与实施策略,已经成为企业数字化竞争的关键分水岭。
本篇文章从数据抓取的本质、不同方案对比、抓取步骤、实施指南、趋势融合等五个方面,为大家综合分析使用RPA进行数据抓取的好处!
.png)
🔍 破题:数据抓取的本质与两大技术路径的抉择
在深入工具对比前,必须厘清一个核心认知:“网页数据抓取”并非单一技术,而是一个涵盖多种解决方案的技术谱系。其核心目标是将散落于各网站的非结构化或半结构化数据,转化为可分析、可利用的结构化信息。当前主流的技术路径可分为两大阵营,各自有完全不同的哲学与实践:
* 传统编程爬虫路径:基于Python(Requests、Scrapy、Selenium等)、Node.js等编程语言,通过代码直接模拟HTTP请求或控制浏览器,精准定位并提取数据。这条路灵活、强大、成本可控,但技术门槛高,维护成本随反爬措施升级而增加。
* RPA自动化路径:以UiPath、实在智能、影刀RPA等为代表。它不关心底层请求,而是完全模拟人类在浏览器中的操作(点击、滚动、输入、复制)。这条路直观、易维护、能处理复杂交互,但通常按机器人或流程许可收费,规模化成本需评估。
选择哪条路径,不取决于技术优劣,而取决于企业的数据需求场景、技术资源与长期战略。
🧭 工具全景:四类抓取方案的深度对比
市场上工具纷繁复杂,但按其核心原理和使用门槛,可清晰归为以下四类:
| 工具类型 | 核心原理 | 代表工具/技术 | 突出优势 | 主要挑战与考量 |
|---|---|---|---|---|
| 1. 编程框架/库 | 发送HTTP请求,解析HTML,或控制浏览器。 | Python (Scrapy, BeautifulSoup, Selenium)、Node.js (Puppeteer, Playwright) | 极致灵活与可控;可定制化应对任何复杂反爬;本地运行,数据安全;社区资源丰富,长期成本低。 | 技术门槛极高,需专业开发团队;开发和维护(应对网站改版、反爬升级)耗时耗力;需自建调度、监控、存储等全套系统。 |
| 2. 可视化采集工具 | 提供图形界面,通过点击网页元素生成采集规则。 | 八爪鱼采集器、后羿采集器、集搜客 | 大幅降低使用门槛,业务人员经培训即可上手;内置代理IP、验证码处理等常见功能;提供云服务和数据管理。 | 处理复杂交互(如登录后数据)和动态加载能力有限;灵活性受工具设计限制;云服务涉及数据出域,可能有合规风险。 |
| 3. 企业级数据抓取平台 | 提供从采集、清洗、管理到交付的一站式云服务。 | 神策数据(某些垂直方案)、以及提供定制服务的云厂商 | 开箱即用,省心省力;强大的抗反爬能力和稳定的数据管道;专业的数据治理和交付能力。 | 成本最高;数据源和采集逻辑可能受限于平台能力;核心数据流程依赖外部服务商,有 vendor lock-in 风险。 |
| 4. RPA机器人流程自动化 | 通过录制或配置,模拟人在电脑上的完整操作流程。 | UiPath、实在智能、影刀RPA、Automation Anywhere | 能处理任何人类可操作的复杂流程(登录、翻页、滑块验证等);与企业现有工作流无缝集成(抓取后直接写入Excel/系统);维护直观(所见即所得)。 | 规模化成本(许可证费用);不适合超大规模、极高并发的纯采集场景;执行效率通常低于直接HTTP请求。 |
🛠️ 核心策略:RPA实施网页抓取的“五步法”
对于选择RPA路径的企业,成功的自动化抓取绝非简单录制,而是一个系统工程。下图展示了一个稳健的实施策略闭环:
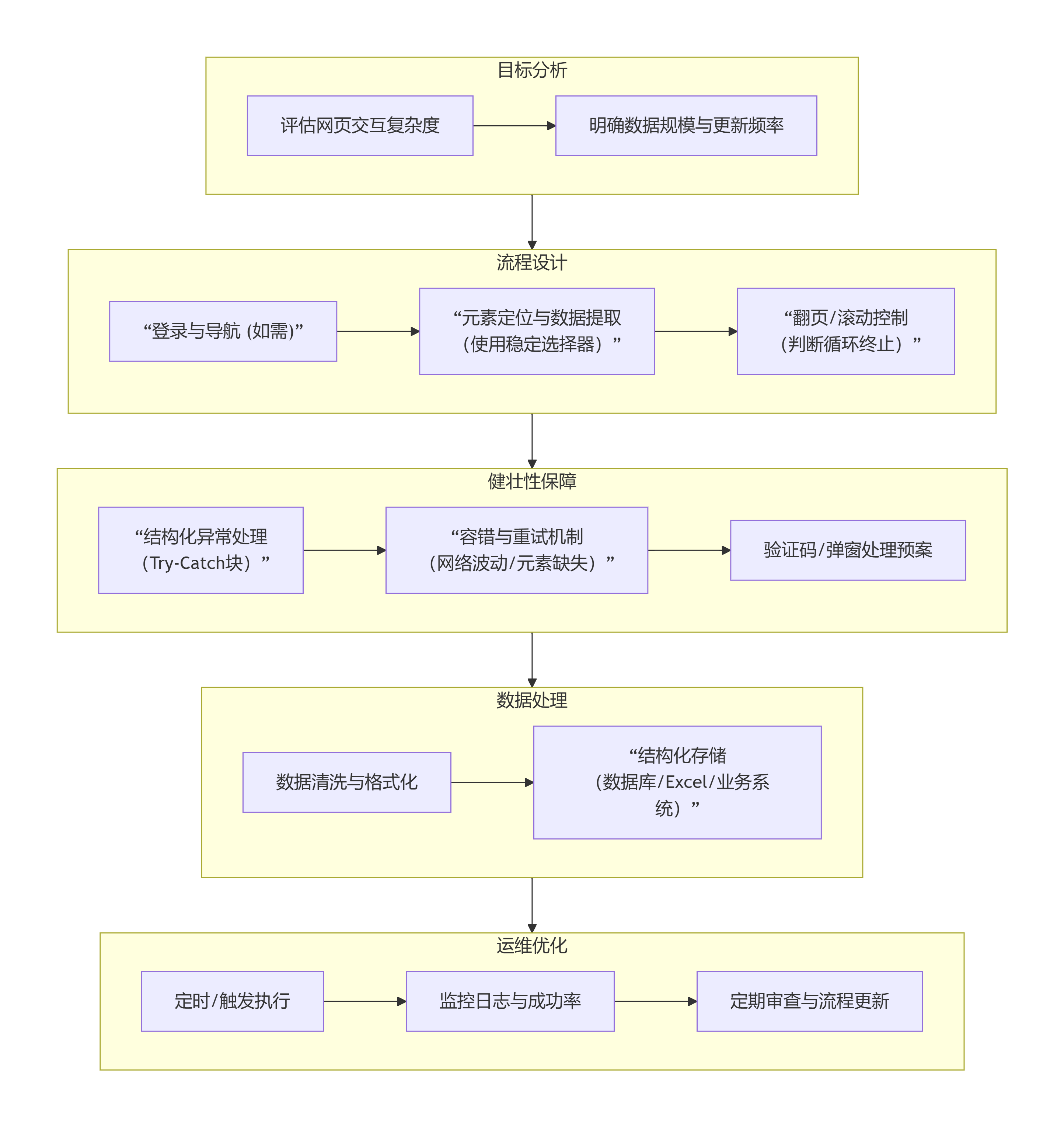
1. 各阶段关键要点解析:
抓取目标分析:这是避免项目失败的基石。必须评估:目标数据是否需要登录?有无复杂验证码?数据是静态加载还是动态生成(如JavaScript渲染)?更新频率如何?这直接决定RPA是否适用。
2. 自动化流程设计:
* 稳定定位:优先使用属性相对稳定的选择器(如 `id`、`name`),而非易变的XPath位置路径。实在智能的“智能屏幕识别”在此有优势。
* 循环控制:设计明确的循环终止条件,如“当‘下一页’按钮失效时停止”,而非固定循环次数。
3. 异常处理与健壮性:这是生产级应用与Demo的关键区别。必须为网络超时、元素未加载、验证码弹出、登录态失效等常见异常设计处理分支,确保机器人能记录错误并尝试恢复或安全停止。
4. 数据清洗与管理:RPA抓取的数据常需清洗(去重、格式化、单位统一)。应规划好数据出口,直接存入数据库或业务系统,形成闭环,避免产生新的“数据孤岛”。
5. 部署监控与优化:利用RPA控制器的调度功能定时执行,并监控运行日志与成功率。定期复审流程,应对目标网站的改版。
🚀 选型与实施决策指南
面对四条技术路径,企业应如何选择?答案不在工具本身,而在清晰的自我评估。
决策流程图与指南:
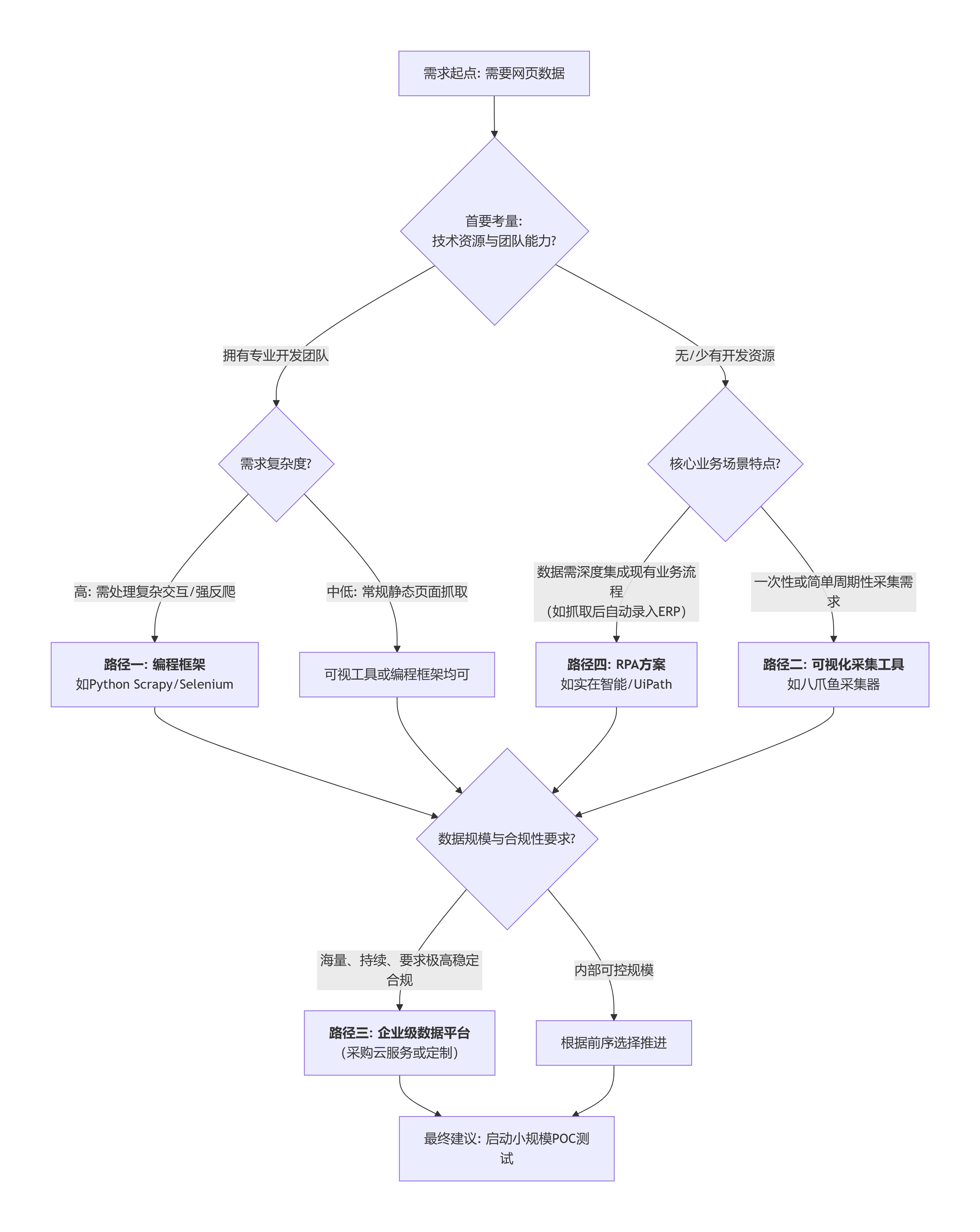
分步行动建议:
1. 成立跨职能小组:包含业务方(定义需求)、IT(评估技术)、法务/合规(评估风险)。
2. 进行POC概念验证:选择1-2个最具代表性的数据源,用候选工具进行为期2-4周的试点,核心验证:稳定性、数据质量、总拥有成本(含人力与许可)。
3. 制定运维规范:无论是哪种工具,都必须建立流程文档、变更管理和监控警报机制。
💡 趋势融合:RPA+AI与超级自动化
未来,单一的抓取技术将向融合演进。“RPA + AI” 将成为处理非结构化数据的利器:
* 计算机视觉(CV):让RPA机器人像人一样“看懂”屏幕上的复杂图表或验证码,增强适应能力。
* 自然语言处理(NLP):对抓取的文本评论、新闻进行实时情感分析与关键信息提取。
* 流程挖掘:自动分析员工手动抓取数据的操作日志,发现和推荐可自动化的机会点。
最终,网页数据抓取将作为关键一环,融入企业 “超级自动化” 的宏大图景,与业务系统、数据分析平台无缝连接,实现从数据获取到决策执行的完整闭环。
结论与行动指南
网页数据抓取不是目的,而是实现业务洞察与自动化的手段。工具的选择,本质上是对企业自身技术债务、资源禀赋和战略耐心的一次务实审视。
核心结论:对于追求业务与IT深度融合、流程端到端自动化的企业,RPA是一条能快速见效、降低集成门槛的卓越路径。但对于超大规模、技术导向的纯数据采集项目,传统编程或专业平台可能更为适合。融合方案(如RPA处理登录与交互,传统爬虫负责大批量提取) 正成为越来越多企业的理性选择。
您的三步速赢计划:
1. 紧急清单:一周内,盘点当前所有依赖人工或脆弱脚本的数据获取需求,按业务价值与失效风险排序。
2. 试点突破:选择榜单首位、且涉及多个系统交互(如从网站抓取数据再填入CRM)的需求,用一款主流RPA工具(如实在智能社区版)启动一个4周内的微型自动化项目。
3. 能力建设:无论选择哪条路径,立即开始培养或招募1-2名兼具业务流程理解与自动化技术的“桥梁型”人才,这是长期成功的核心保障。
常见问题解答(FAQ)
🤔 Q1:我们公司用Python爬虫已经很多年了,为什么要考虑RPA?
A:如果现有爬虫栈稳定且团队维护能力强,不一定需要切换。但RPA在以下场景具有独特价值:1)业务部门有紧急、零散的数据需求,IT部门排期过长;2)数据获取流程涉及多个需要人工交互的内部系统(如抓取数据后还需登录内部OA审批);3)目标网站反爬策略基于行为特征,而RPA模拟真人操作更易规避。RPA可成为对传统爬虫体系的重要补充,而非替代。
🧩 Q2:使用可视化采集工具或RPA,数据安全与合规性如何保障?
A:这是关键问题。本地部署的RPA或采集工具,数据不经过第三方服务器,安全性最高。使用云服务SaaS模式时,务必确认服务商的数据安全认证、隐私协议,并评估数据出域风险。所有抓取行为,无论用何种工具,都必须严格遵守《网络安全法》《数据安全法》《个人信息保护法》及目标网站的`robots.txt`协议,避免对目标网站造成负担。
🛠️ Q3:RPA机器人被抓取网站封禁IP怎么办?
A:RPA实施中必须考虑此风险。策略包括:1)降低访问频率,在流程中设置随机等待时间;2)使用代理IP池(部分高端RPA平台支持集成);3)对于关键任务,准备多个账号轮换使用;4)设计监控流程,当机器人检测到“访问受限”页面时,自动暂停并报警,而非持续尝试触发更严厉封禁。


