















































什么是无监督学习
无监督学习是一种机器学习方法,它不需要预先标记好的训练数据,而是通过对数据的自动处理和分析,发现数据中的隐藏模式、结构和规律。

以下是关于无监督学习的详细解释:
一、定义与特点
定义:
无监督学习是指在没有明确输出标签的情况下,算法自动从数据中提取有意义的信息或模式。
与监督学习不同,无监督学习不需要事先定义数据的标签或类别。
特点:
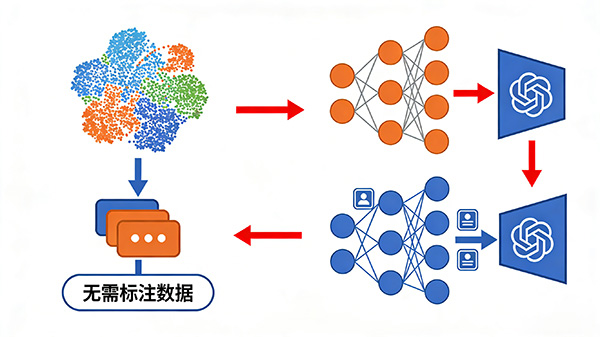
无需标注数据:无监督学习不需要事先对数据进行标注,这大大节省了人力成本。
自动发现模式:算法能够自动从数据中发现隐藏的模式和结构。
结果难以解释:由于无监督学习的结果往往是隐式的或不可直接量化的,因此其效果难以用传统的性能指标来评估。
二、核心原理
无监督学习的核心思想是通过对数据的统计特征、相似度等进行分析和挖掘,利用密度估计、聚类和降维等技术来捕获和发现数据隐藏的内在结构和模式。
常见的无监督学习算法包括:
聚类算法:如K-Means聚类、层次聚类、DBSCAN等,用于将数据分成不同的组或簇,使得同一组内的数据相似度高,不同组之间的相似度低。
降维算法:如主成分分析(PCA)、t-分布随机邻域嵌入(t-SNE)等,用于将高维数据映射到低维空间,以减少特征维度和数据复杂性。
生成模型:如生成对抗网络(GANs)、变分自编码器(VAEs)等,能够学习数据的概率分布,并生成新的、类似于训练数据的样本。

三、应用领域
无监督学习在各个领域都有广泛的应用,包括:
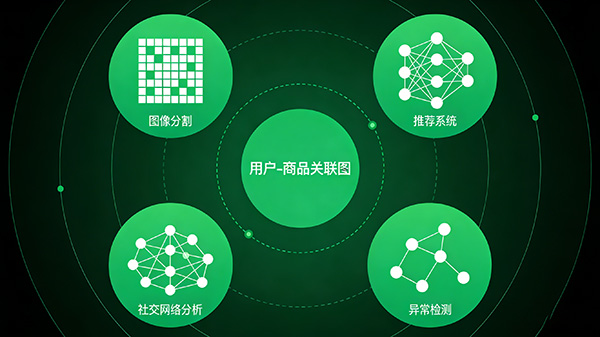
图像分割:在计算机视觉领域,无监督学习被用于图像分割任务,通过对图像中的像素进行聚类,将图像分成不同的区域。
推荐系统:无监督学习通过分析用户的消费行为和喜好,推荐类似的产品或服务。
社交网络分析:无监督学习用于发现社交网络中的社区结构和关系。
异常检测:无监督学习用于识别与大多数数据点显著不同的数据点,这些异常点通常代表着故障、欺诈或其他值得关注的事件。
生物信息学:无监督学习用于基因表达数据分析、蛋白质结构预测等。
自然语言处理:无监督学习用于主题建模、词嵌入等技术,发现文本中的主题、提取关键词等。
四、优势与挑战
优势:
处理未标注数据:无监督学习能够处理大量的未标注数据,从中提取有价值的信息。
节省人力成本:无需对数据进行标注,节省了人力成本和时间成本。
发现隐藏模式:能够自动发现数据中的隐藏结构和规律,为决策提供有力支持。
挑战:
结果难以解释:无监督学习的结果往往难以解释和评估。
算法选择困难:不同的无监督学习算法适用于不同的数据集和问题场景,选择合适的算法需要丰富的经验和专业知识。
计算复杂度高:一些无监督学习算法的计算复杂度较高,需要较强的计算能力支持。

总结来看,无监督学习是一种强大的工具,能够从未标记数据中提取有价值的信息,并应用于各种领域。
随着数据的不断增长和算法的不断发展,无监督学习将在更多领域发挥重要作用。


