















































在处理多模态数据时,大模型如何实现跨模态学习?
在处理多模态数据时,大模型实现跨模态学习的方式涉及多个层面,包括数据预处理、模型架构设计、训练策略以及算法优化等。
以下是大模型实现跨模态学习的主要步骤和关键点:
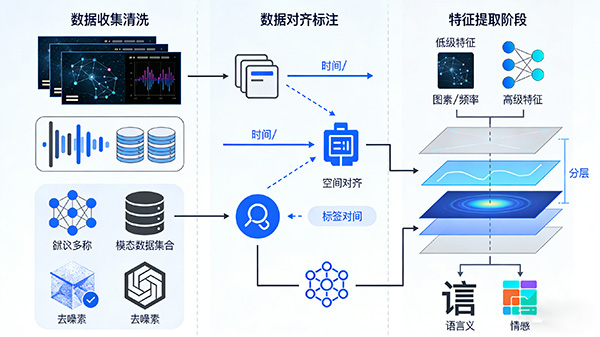
一、数据预处理
数据收集与清洗: 收集来自不同模态的数据,如文本、图像、音频和视频等。
对数据进行清洗,去除噪声和异常值,确保数据的质量和一致性。
数据对齐与标注: 对不同模态的数据进行对齐,确保它们在时间、空间或其他维度上的一致性。
对数据进行标注,为模型的训练提供监督信息。
特征提取: 使用适当的特征提取方法,从每种模态的数据中提取有用的特征。
这些特征可以是低级的(如像素值、频率等)或高级的(如语义特征、情感特征等)。
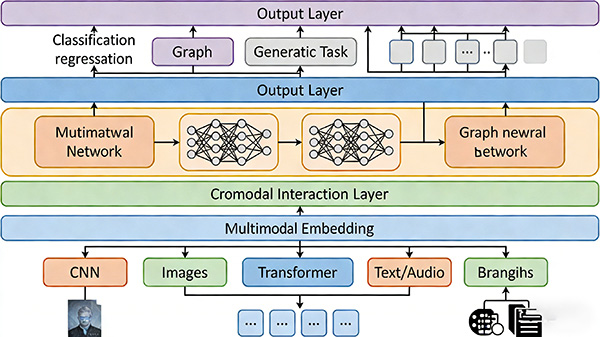
二、模型架构设计
多模态嵌入层:
设计一个能够将不同模态数据映射到同一嵌入空间的嵌入层。
这通常涉及到使用深度学习技术,如卷积神经网络(CNN)用于图像、循环神经网络(RNN)或变换器(Transformer)模型用于文本和音频等。
跨模态交互层:
在嵌入层之后,设计跨模态交互层以允许不同模态之间的信息交换和融合。
这可以通过注意力机制、图神经网络(GNNs)或其他高级交互策略来实现。
输出层:
根据具体任务设计输出层,如分类、回归、生成等。
输出层应能够处理跨模态信息并产生有意义的输出。
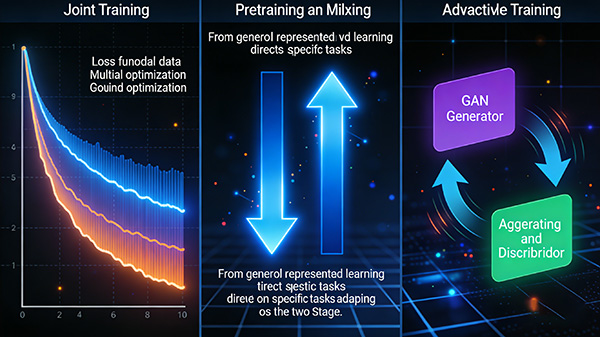
三、训练策略
联合训练:
采用联合训练策略,同时优化多个模态的数据。
这通常涉及到定义一个统一的损失函数,该函数能够同时考虑来自不同模态的监督信息。
预训练与微调:
先使用大量无标签或弱标签的多模态数据进行预训练,以捕获跨模态之间的通用表示。
然后,在特定任务的数据集上进行微调,以优化模型在特定任务上的性能。
对抗性训练:
使用生成对抗网络(GANs)等对抗性训练策略,以生成更真实、更多样化的跨模态数据,从而提高模型的泛化能力。
四、算法优化
优化算法选择:
选择适合处理多模态数据和跨模态学习的优化算法,如随机梯度下降(SGD)、Adam等。
这些算法应能够快速收敛并避免过拟合。
超参数调优:
对模型的超参数进行调优,如学习率、批量大小、嵌入维度等。
这通常涉及到使用网格搜索、随机搜索或贝叶斯优化等策略。
正则化与剪枝:
使用正则化技术来防止模型过拟合,并通过剪枝等技术来减少模型的复杂性和计算成本。
五、应用实例
跨模态学习在大模型中的应用实例非常丰富,包括但不限于:
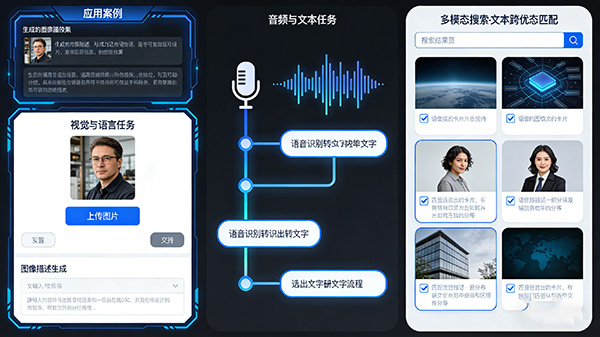
视觉与语言任务:
如图像描述生成、视觉问答(VQA)等,这些任务需要模型理解图像和文本之间的关联。
音频与文本任务:
如语音识别、语音合成等,这些任务需要模型理解音频信号和文本内容之间的对应关系。
多模态检索:
如图像与文本的跨模态检索,这要求模型能够在不同模态的数据之间建立有效的索引和匹配机制。
通过上述步骤和关键点,大模型能够有效地处理多模态数据并实现跨模态学习,从而在更广泛的应用场景中发挥其强大的能力。
