















































对于包含大量文本的数据集,如何进行文本数据清洗?
对于包含大量文本的数据集,进行文本数据清洗是一个复杂但至关重要的过程,它直接关系到后续文本分析、情感分析、文本分类和机器学习等任务的准确性和效率。

以下是一个详细的文本数据清洗步骤指南:
一、理解数据背景
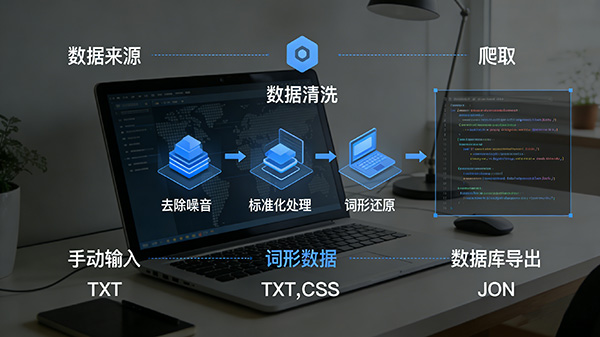
数据来源:了解数据的来源,包括爬取、手动输入、数据库导出等,以便识别可能存在的特定问题。
数据格式:查看数据的原始格式,如TXT、CSV、JSON等,确定后续处理的方式。
业务背景:理解数据的业务背景,明确清洗的目标和预期结果。
二、数据预检查
数据概览:使用统计方法(如均值、中位数、方差等)和可视化工具(如直方图、箱线图等)对数据集进行概览,识别异常值、缺失值等。
特殊字符和HTML标签:检查文本中是否包含HTML标签、特殊字符(如 、©等)等需要去除的元素。
重复数据:识别并标记重复或高度相似的文本记录。
三、制定清洗规则
基于规则的清洗:制定一系列规则来清洗文本数据,这些规则可以包括正则表达式、模糊匹配和语义规则等。
例如,去除所有HTML标签、特殊字符,以及根据业务需求定义重复数据的阈值。
停用词列表:创建或采用现有的停用词列表,去除文本中频繁出现但无实际意义的词语,如“的”、“了”、“是”等。
四、执行清洗操作
去除噪声:根据制定的规则去除文本中的噪声,包括特殊字符、HTML标签、停用词等。
标准化处理:对文本进行标准化处理,如将所有文本转换为小写、统一编码格式(如UTF-8)等,以确保数据的一致性。
词形还原和词干提取:对于需要进行文本分析的任务,可以考虑使用词形还原和词干提取技术将单词还原为词根形式,有助于对相似的单词进行分组。
处理缺失数据:对于缺失值,根据业务需求选择填充缺失值(如使用众数、平均数或特定占位符)或删除缺失记录的策略。
重复数据删除:根据预检查阶段标记的重复数据,执行删除操作。
注意保留原始数据的一个副本或记录,以防需要恢复。
五、验证和监控
清洗效果评估:通过对比清洗前后的数据质量和准确率等指标来评估清洗效果。
可以使用人工检查或自动化测试工具来验证清洗结果的准确性。
定期监控:对于持续更新的数据集,需要定期监控数据质量,确保清洗过程的有效性和一致性。
六、文档记录
清洗步骤记录:详细记录所采取的清洗步骤和策略,包括任何假设、决策和改变。
这有助于未来的审计和改进工作。
版本控制:对数据集的不同版本进行管理,以便在出现问题时可以追溯和恢复到早期的状态。
七、工具和技术选择
文本处理库:利用专门的文本处理库(如pandas、NLTK、spaCy等)来加速清洗过程并提高准确性。
正则表达式:对于需要精确匹配和替换文本模式的场景,正则表达式是一个强大的工具。
自动化工具:考虑使用自动化工具(如ETL工具、数据清洗软件等)来简化清洗流程并减少人工干预。
总之,对于包含大量文本的数据集进行清洗是一个涉及多个步骤和技术的复杂过程。
通过遵循上述指南并选择合适的工具和技术,可以有效地提高数据质量并为后续的文本分析任务奠定坚实的基础。
