
















































语音识别的两个基本模型
2026-05-30 16:12:00阅读 4159
语音识别的两个基本模型是语言模型(Language Model)和声学模型(Acoustic Model)。
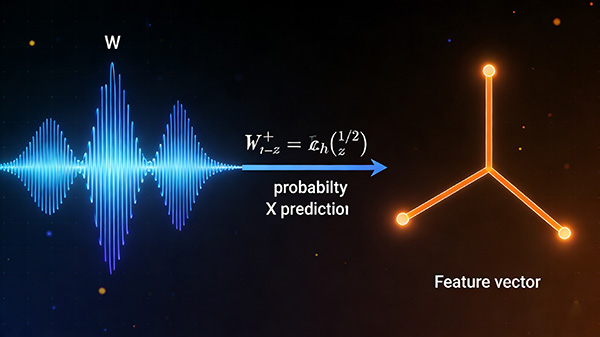
语言模型主要用于预测某词或词序列的概率。声学模型则用于预测通过词W的发音生成特征X的概率。

声学模型是自动语音识别系统中最底层、最关键的部分,其建模的好坏会直接影响语音识别系统的识别效果和鲁棒性。声学模型利用概率统计的模型对带有声学信息的语音基本单元建立模型,描述其统计特性,从而有效衡量语音的特征矢量序列和每一个发音模板之间的相似度,有助于判断该段语音的声学信息,即语音的内容。
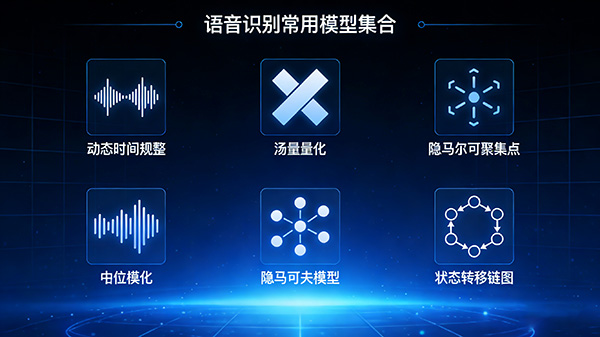
语音识别常用的模型还包括动态时间规整(Dyanmic Time Warping)、矢量量化(Vector Quantization)、隐马尔可夫模型(Hidden Markov Models)等。
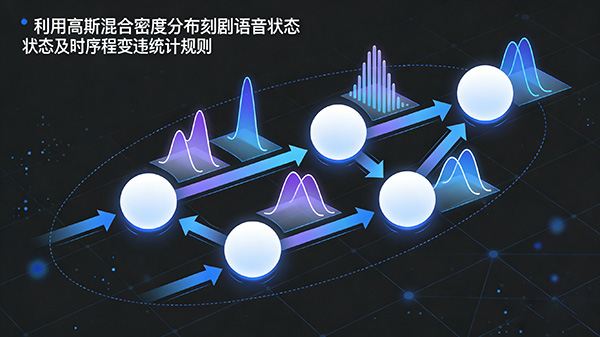
其中,隐马尔可夫模型利用高斯混合密度分布刻画语音状态(例如音素)以及语音状态之间的时序变迁的统计规律,是语音识别中的重要模型之一。
这些模型和技术的应用,使得语音识别系统能够更准确地理解和识别用户的语音输入,从而实现更自然、高效的人机交互。
分享:

