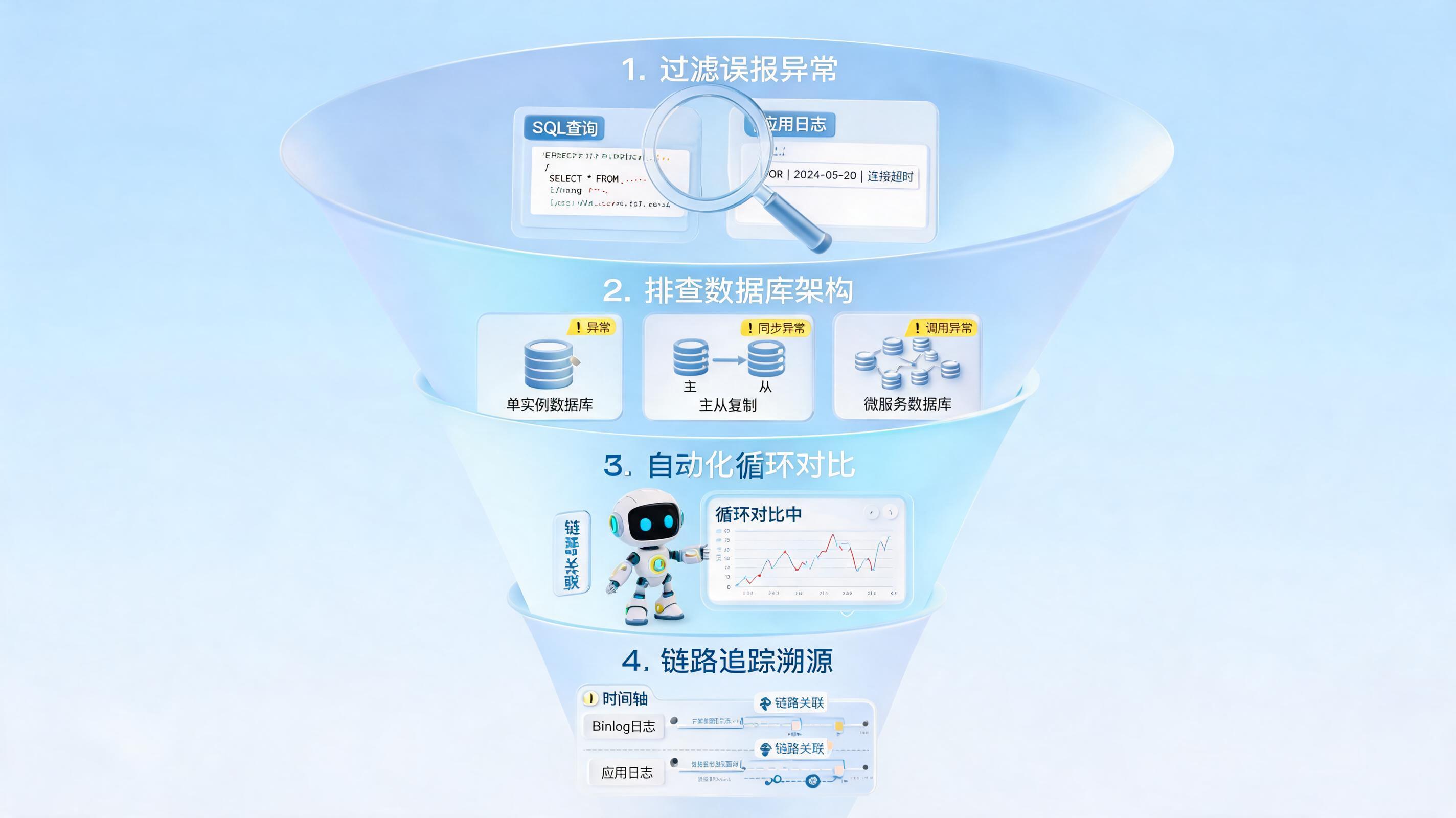
怎么自动校验理赔条款责任?四层闭环方案
自动校验理赔条款责任,本质不是把条款交给AI问一遍,而是把保单责任、免责、等待期、病历、发票、赔付标准和流程节点转成可计算链路:系统先结构化资料,再做责任匹配、金额校验、异常解释和流转复核,才能真正替代大部分初审。

一、先把理赔责任校验拆成4个判断
很多项目做不深,不是模型不够强,而是把一个复杂问题压成一句问答。自动校验至少要同时回答4件事。
- 责任是否成立:出险事件、诊疗行为或费用项目,是否落在保单责任清单内。
- 是否触发免责:既往症、等待期、除外责任、自费项目、非约定医院、材料缺失等是否命中拒赔或部分赔付条件。
- 金额是否合理:单项限额、年度限额、免赔额、赔付比例、重复发票、金额逻辑一致性是否通过。
- 证据是否充足:病历、处方、票据、保单信息、身份信息能否互相印证。
为什么很多系统只做到半自动
因为OCR只能看见文字,规则引擎只能比对已知条件,单纯大模型又容易在长链路、多文档、强合规场景里给出看似通顺但不可审计的答案。理赔责任校验必须把识别、推理、行动、留痕连起来。
二、可落地的自动校验架构,通常是4层闭环
| 层级 | 核心任务 | 关键输出 |
|---|---|---|
| 资料层 | OCR与IDP抽取病历、发票、费用清单、保单字段 | 结构化字段与置信度 |
| 规则层 | 把责任、免责、等待期、限额、赔付比例转成机器可执行规则 | 规则树与版本库 |
| 核验层 | 做身份、时间、医院、金额、责任范围的交叉校验 | 通过项与疑点项 |
| 处置层 | 输出通过、部分赔付、补件、转人工、拒赔,并保留日志 | 结果码、原因码、审计轨迹 |
第1层:资料结构化
先把多源材料读懂,尤其是病历首页、诊断结论、发票金额、费用明细、就诊时间、保单生效时间。没有结构化,后面的责任判断都只是人工复制粘贴。
第2层:条款责任映射
把自然语言条款拆成主体、事件、时间、金额、排除项。例如住院发生在等待期后、医院等级达标、费用项目属于责任范围,才进入赔付计算;否则直接输出拒赔或补件原因。
第3层:交叉核验
- 身份一致性:被保险人、就诊人、票据抬头是否一致。
- 时间一致性:就诊日期是否晚于保单生效且满足等待期要求。
- 金额一致性:发票总额、费用清单、小项合计、保额上限是否自洽。
- 责任一致性:诊断、治疗项目、医院类别是否命中责任或免责条款。
第4层:结果输出与治理
系统不只要给结论,还要给理由。Gartner在2024年将AI TRiSM列为战略趋势之一,并提示到2026年,把透明度、信任、风控和安全纳入AI治理的组织,其模型落地成效与用户采纳有望获得50%级别改善。对理赔而言,这意味着每一次自动结论都要能回溯到字段、规则和版本。
三、真正高效的流程,不是全部自动通过,而是异常优先
- 接收报案与影像资料
- OCR与IDP提取核心字段
- 匹配保单版本与责任规则库
- 执行责任、免责、金额、证据四类规则
- 生成原因码与解释文本
- 低风险案件自动通过,高风险案件转人工复核
- 沉淀日志、截图、PDF附件,满足审计追溯
一个适合医疗理赔初审的逻辑树
保单有效?
├─否:拒赔并说明保单状态
└─是:进入责任判断
等待期已过?
├─否:拒赔或部分赔付
└─是:进入资料核验
病历、发票、清单齐全?
├─否:补件
└─是:进入责任匹配
诊断与费用项目在责任范围内?
├─否:拒赔或剔除不赔项目
└─是:计算免赔额、比例与限额,输出赔付金额
为什么要把补件和拒赔分开
补件是证据不足,拒赔是规则不满足。两者混在一起,既影响客户体验,也会让后续模型训练样本失真。
四、最容易把系统做坏的,不是模型,而是规则治理
- 条款版本混乱:同一险种不同年份条款并不完全一致,版本不清,校验结果一定失真。
- 免责口径不统一:理赔、核保、客服口径不一致,系统就会出现同案不同判。
- 历史案件无标签:没有通过、补件、拒赔的标准结果码,模型很难稳定学习。
- 系统割裂:影像系统、核心保单系统、OA、财务系统彼此分散,人工搬运最容易出错。
- 只追求自动通过率:理赔风控更重要的指标,其实是疑点发现率、原因解释率和复核命中率。
上线前,建议先设3个阈值
- 字段置信度阈值:核心字段识别置信度不足,直接转人工,不做自动赔付。
- 规则冲突阈值:同一案件命中相互矛盾条款时,强制复核。
- 金额敏感阈值:高赔付金额、异常频次、特殊病种案件,优先走人工复核。
McKinsey在2023年研究中估计,生成式AI每年可为全球经济新增2.6万亿至4.4万亿美元价值;但在保险这类强监管流程里,真正能兑现价值的,不是单次回答更像人,而是流程更可解释、更稳定、更可审计。
五、某类业务场景下,自动校验怎么落地
在医疗理赔初审场景里,系统会先核对病历与发票,再判断是否符合理赔范围;命中责任范围且资料齐全的案件进入自动通过,疑点案件高亮超标项或缺失项,并生成打回原因后流转人工复核。
- 输入材料:病历、发票、费用清单、保单条款、身份信息
- 机器动作:字段抽取、责任匹配、金额核算、异常解释、流程流转
- 人工动作:处理灰区条款、医学争议、欺诈疑点、特殊授权
如果企业还要把PDF生成、审计追踪、权限隔离、OA流转串起来,单点工具往往不够,需要让识别与执行形成一条闭环链路。例如实在Agent可把文档理解、跨系统操作、异常说明和任务回传串成一个流程,减少人工在保司系统、OA、影像系统之间反复切换。
某类业务场景下的客户实践:医疗理赔初审会核对病历与发票,判断是否符合理赔范围;在其他规则密集型审核场景中,系统还能自动高亮超标项并生成打回原因,流转至审批人处理。数据及案例来源于实在智能内部客户案例库。
六、企业上线前,先看这份检查清单
- 条款是否做了版本化管理
- 责任、免责、等待期是否拆成机器可执行规则
- 病历、票据、清单字段模板是否覆盖主流版式
- 是否定义通过、补件、拒赔、转人工四类结果码
- 是否保留审计日志、操作截图、规则命中记录
- 是否设置人机协同兜底与抽检机制
❓常见问题
Q1:规则引擎和大模型,谁更适合理赔条款校验?
A:两者要配合。规则引擎负责等待期、赔付比例、免责条款等硬规则,大模型负责文档理解、字段抽取、原因解释和灰区辅助判断。只有二者结合,才能既稳又能适应复杂材料。
Q2:自动校验能不能直接替代核赔员?
A:对高频、标准化、低争议的初审案件,可以替代大量重复劳动;但涉及医学争议、欺诈风险、特殊授权和复杂责任解释时,仍需要人工终审。
Q3:没有干净历史数据,能不能先做?
A:可以。最稳妥的方法是先从规则清晰、资料固定、量大的场景起步,先建立结果码和条款版本库,再逐步把历史案件反标为训练样本。
参考资料:2024年 Gartner《Top Strategic Technology Trends for 2024: AI TRiSM》;2023年6月 McKinsey《The economic potential of generative AI: The next productivity frontier》;2026年3月28日《IDP全场景智能审核解决方案》及相关客户实践材料。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。