















































Agent的长期记忆通常不包含哪项内容
对于一个企业而言,智能体是否有长期记忆被作为它是否能够持续服务和协同的一个基准。
但智能体的长期记忆并不是和人的记忆是一个概念,要看清楚其中的区别与边界,才能避免使用智能体的风险。
一、长期记忆:智能体为什么会持续的进化
智能体的长期记忆,简单来说,就是与智能体进行上下文对话的时候可能对话次数过多,但智能体能够记住以往对话内容,具有“思考”的回答,能够满足用户的一些个性化需求。
落实到实际场景,有长期记忆的智能体会进行内容或数据的分析、处理与过滤,有利于项目的执行。
二、智能体的记忆边界是什么
虽然智能体的技术一直在进步,但是有一个绝不能跨越的原则就是对数据或内容的隐私性保护,这就是智能体的记忆边界。我们有三类信息,智能体是基本不进行保存的。
1. 瞬时、琐碎的交互数据不保存。保存这种数据会影响对话的流畅性。而且这种数据的价值参考性低的同时还有很高的隐私风险,所以不能保存。
2. 对于完整的原始文档与媒体文件,只保存其中的精髓即可。这样做的目的是为了提高检索的效率和节约储存的成本。只提取关键内容就能进行执行。
3. 对于系统底层的环境数据和实时状态,基本可以不用进行保存。智能体运行时产生的活动一般都是高动态且与核心执行任务关系不大的底层信息,所以很少会被长期记忆收取。

三、智能体的记忆是怎样形成的
智能体的记忆系统自带一套主动的过滤机制,这个机制可以起到保障信息安全的作用,只有安全有有价值的信息才可以进入到智能体的记忆中。
第一步:输入过滤。系统会将刚进入的信息进行初步筛选,标记或者直接过滤掉无关的信息。
第二步:处理摘要。智能体会运用自然语言理解技术把过长的聊天内容压缩成摘要或者关键词。
第三步:储存优化。系统会根据信息的重要程度来决定对信息是要做成标签还是永久保存,又或是定期清理。
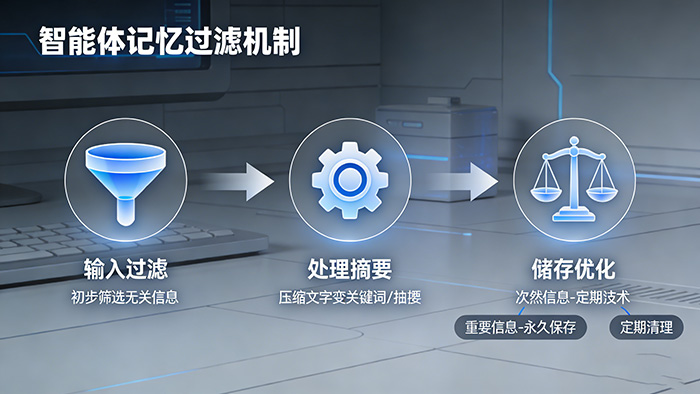
这种过滤机制让智能体变得既高效安全又很能用。
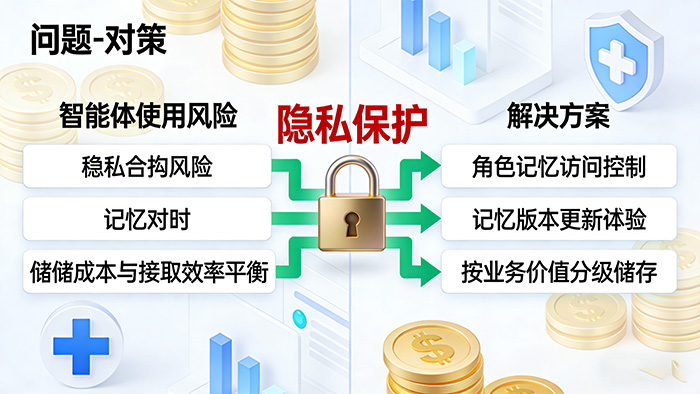
四、使用智能体的风险和困扰及应对方法
使用智能体时,最应该规避的就是隐私合规的风险,尤其在金融、医疗 这些监管强度高的行业,数据的保密性要求是极高的,智能体一旦把数据信息泄露出去,会是一个很大的风险,所以,一个常见的应对方法就是建立基于角色的记忆访问控制,这样智能体可以自动识别敏感信息来规避信息泄露的问题。
同时,智能体还可能出现记忆与当下相比是相对过时的状态,直接使用可能造成给用户提供错误信息的状况,这时,就需要对智能体的记忆系统进行版本更新与校验,以此来保证信息与实际情况相对应。
除了这些风险和困扰,还有就是储存成本与检索效率的平衡问题。如果把信息全部储存下来的话,不光成本变高还会导致智能体检索的速度也变慢,这时,就需要企业根据业务价值进行针对性的服务,对VIP客户可以保存详细的记忆,而对于普通的咨询,只需要存一个模式化摘要就行。
五、智能体长期记忆技术的未来发展方向
未来,智能体的长期记忆技术将会朝着更精准、更可控的方向发展。未来,智能体对上下文的重要优先级评估将更上一层楼,同时,对于隐私数据的保护技术将uhi深度的融入记忆系统,让智能体的使用更加安全可靠,并且智能体的记忆将会朝着模块化、可组合性发展,使智能体的应用更加灵活。

常见问题(FAQ)
Q1:长期记忆有限制,那企业最该让智能体记住什么?
A1: 优先级应该是:经常被调用的业务知识、用户的个性化偏好、经过验证的有效解决方案,以及跨会话的项目上下文。举个例子,在客服场景中,像实在Agent这样的智能体,会被设定为重点记忆常见问题的标准答案和特定用户的沟通习惯,而不是去记每次对话里的“早上好”、“吃了吗”这些寒暄细节。
Q2:如果智能体忘了重要信息,还能补救吗?
A2: 可以的,通常有管理后台进行操作。主要方法有:1. 手动更新知识库:管理员可以直接向关联的知识库里添加正确信息;2. 强化训练:通过新的对话数据或专门数据集,重新训练相关模块;3. 重建记忆索引:调整向量模型或检索策略,提高特定信息的优先级。当然,这都要求系统本身具备良好的可管理性。


