Agentic RAG 和普通 RAG 的区别:从“检索后生成”到“主动规划”
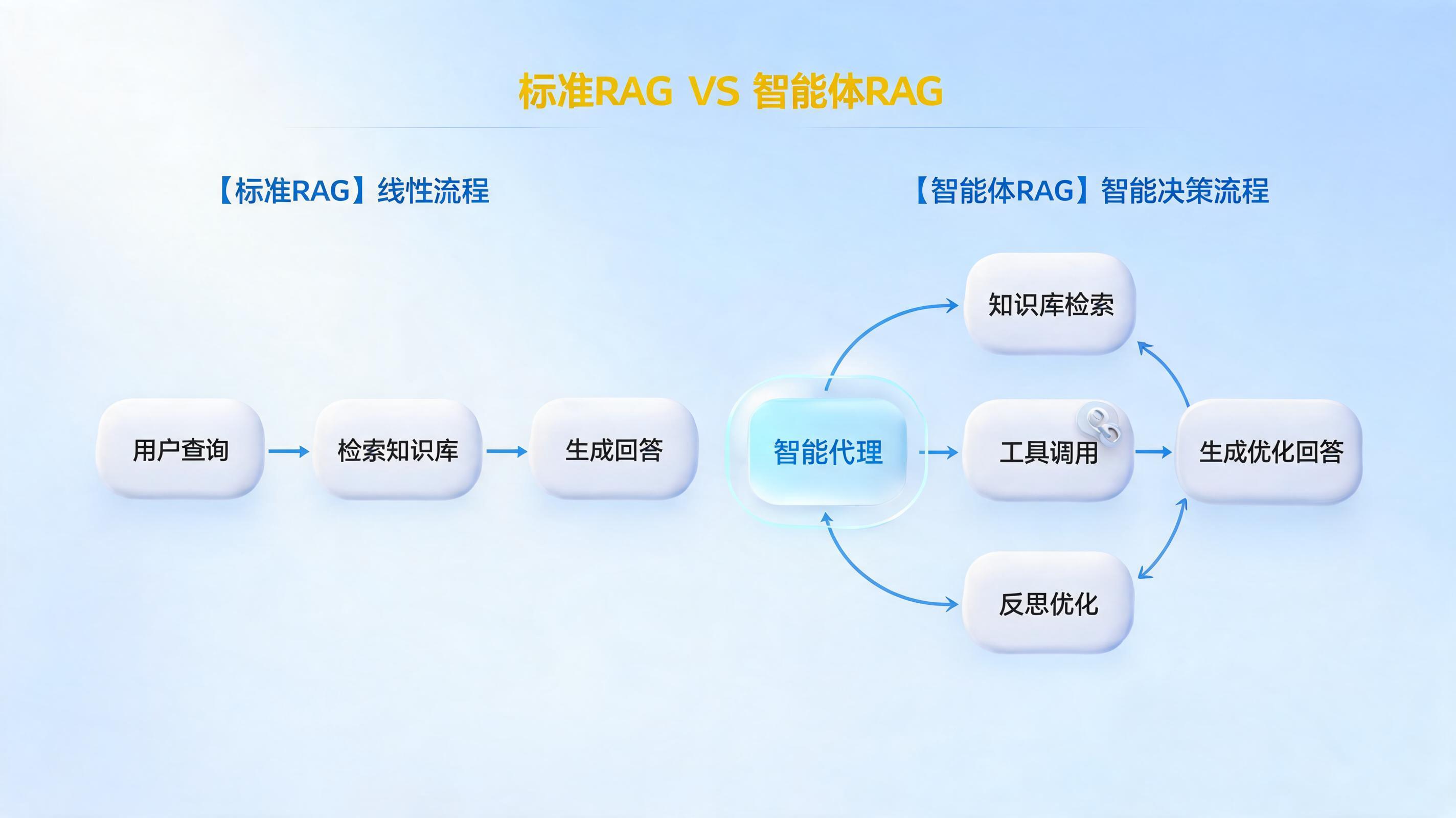
普通 RAG(Retrieval-Augmented Generation,检索增强生成)是一种将外部知识库检索与大语言模型生成相结合的技术架构。它的工作流程是固定的:用户提问 → 将问题向量化 → 从知识库中检索相关文档片段 → 将问题和检索结果一起交给大模型 → 生成答案。
Agentic RAG 则是在 RAG 基础上引入“智能体”的自主规划与决策能力。它不是一次性检索然后生成,而是让一个 AI Agent 自主判断“我是否需要检索?”、“检索结果够不够?”、“是否需要换个方式再查一次?”、“是否需要调用其他工具(如计算器、数据库查询)来辅助回答?”。
两者的核心区别可以总结为:普通 RAG 是“问-查-答”的线性流程,Agentic RAG 是“目标-规划-行动-评估-再行动”的循环迭代。下面从几个维度拆解。
📌 本文大纲
- 普通 RAG 的工作原理与局限
- Agentic RAG 的工作原理与核心能力
- 直观对比:一个复杂查询的两种处理方式
- 技术架构差异:从单次检索到多步推理
- 适用场景与选型建议
- 总结与推荐
一、普通 RAG 的工作原理与局限
普通 RAG 的流程可以概括为三个步骤:
- 索引:将企业文档(PDF、Word、网页等)切分成小块,通过嵌入模型转换为向量,存储在向量数据库中。
- 检索:用户提问后,将问题也转换为向量,在向量数据库中查找最相似的 K 个文档片段。
- 生成:将检索到的片段与原始问题一起输入大模型,生成最终答案。
普通 RAG 的优势:实现简单、响应快、成本可控,适合大多数常规问答场景。
普通 RAG 的局限:
- 单次检索可能不够:复杂问题往往需要多轮检索。例如“对比 A 产品和 B 产品的定价策略”,可能需要先分别查找两者的定价文档。
- 无法判断检索质量:如果检索到的片段与问题不相关,大模型可能会生成错误答案(称为“检索失败”),但系统不会意识到这一点。
- 缺乏工具调用能力:如果用户问“去年 Q3 和 Q4 的销售额增长率是多少”,需要先获取两个季度的数值再计算,普通 RAG 无法自主完成这个计算步骤。
- 无法处理需要多步推理的复杂问题:比如“我们的哪些客户购买了产品 X 而且位于华东地区?列出他们的联系人邮箱”——这需要先筛选客户名单,再查询地区,再提取联系人信息。普通 RAG 只能回答“如何做”而不能“替你做”。
二、Agentic RAG 的工作原理与核心能力
Agentic RAG 将 RAG 嵌入到一个智能体(Agent)的“感知-规划-行动”循环中。典型流程如下:
- 理解目标:Agent 接收用户提问,将其解析为一个明确的目标。
- 制定计划:Agent 自主生成一个多步计划,决定需要检索什么、是否需要多次检索、是否需要调用其他工具。
- 执行行动:Agent 执行计划中的每一步——可能是检索知识库,也可能是调用计算器、执行 SQL、访问 API 等。
- 评估结果:Agent 检查每一步的结果是否满足需求,如果不满足则调整计划、重新检索或换一种方式。
- 生成答案:当 Agent 确信收集了足够信息后,综合所有结果生成最终回答。
Agentic RAG 的核心能力:
- 多跳检索:能够根据中间结果决定下一步检索方向。例如先搜索“A 产品的定价”,再基于这个结果搜索“A 产品 vs B 产品 定价对比”。
- 检索质量自评:Agent 可以判断“检索到的内容是否相关”,如果不相关会尝试改写查询词、换个检索策略甚至放弃检索转用自身知识。
- 工具集成:除了知识库检索,Agent 还可以调用计算器、代码解释器、数据库查询、网页搜索等工具。例如回答“去年销售额增长率”时,Agent 会先检索销售额数据,然后用计算器算出增长率。
- 自适应迭代:当一次回答不够完整时,Agent 可以追问用户、要求澄清或主动补充信息。
三、直观对比:一个复杂查询的两种处理方式
假设用户问:“今年入职的软件工程师中,有哪些人参加过 Python 培训?请列出他们的名字和培训日期。”
普通 RAG 的做法:
- 将整个问题向量化,从知识库中检索片段。
- 可能找到“2025年Python培训名单”文档和“入职人员名单”文档,但两个文档是分离的。
- 大模型基于片段生成答案:可能只能列出参加过培训的人,但不知道哪些是今年入职的;或者只能列出今年入职的人,但不知道培训情况。最终答案往往不准确或不完整。
Agentic RAG 的做法:
- 第 1 步:Agent 拆解目标 → 需要两份数据:今年入职的软件工程师名单 + Python 培训记录。
- 第 2 步:执行检索 A → “提取今年入职的所有软件工程师姓名”。
- 第 3 步:执行检索 B → “提取参加过 Python 培训的员工名单及培训日期”。
- 第 4 步:Agent 将两份结果在内存中进行交集匹配(或者调用代码工具自动执行)。
- 第 5 步:生成表格格式的答案,列出姓名和培训日期。
- 第 6 步(可选):如果匹配结果为空,Agent 自主询问“是否需要扩大培训查询范围,包括线上课程?”
四、技术架构差异:从单次检索到多步推理
| 维度 | 普通 RAG | Agentic RAG |
|---|---|---|
| 检索次数 | 单次 | 多次(根据需要迭代) |
| 查询路由 | 无,直接检索全部 | 有,可路由至不同知识库或工具 |
| 检索策略 | 固定(如余弦相似度) | 动态(可改写查询、调整 top-k、混合检索) |
| 结果验证 | 无 | Agent 会自我评估检索质量 |
| 工具集成 | 无或静态 | 动态选择工具(计算、代码、API等) |
| 决策能力 | 无 | Agent 决定何时检索、何时停止、何时转人工 |
| 复杂问题处理 | 较弱 | 强(多跳推理、中间结果组合) |
从实现角度看,普通 RAG 可以用简单的“向量数据库 + LLM 调用”搭建,而 Agentic RAG 需要一套完整的 Agent 框架(包括规划模块、记忆模块、工具注册中心和执行器)。
五、适用场景与选型建议
选普通 RAG,如果你:
- 需要做 FAQ 问答、文档摘要、知识库检索等“一问一答”式场景
- 用户问题相对简单、不需要多步推理
- 对响应速度要求高,对完美准确率要求不那么极端
- 不想引入 Agent 框架的复杂度和成本
选 Agentic RAG,如果你:
- 用户问题往往涉及多个信息源、需要组合推理(如“找出同时满足条件 A 和 B 的记录”)
- 需要 Agent 自主决定检索策略、验证结果、主动追问
- 需要集成计算、代码执行等工具来完成端到端任务
- 愿意接受稍长的响应时间以换取更高的答案准确率和任务完成率
六、总结
普通 RAG 和 Agentic RAG 的本质区别在于 “检索”在整个系统中的角色:普通 RAG 中检索是一次性、前置的步骤,结果直接用于生成;Agentic RAG 中检索是迭代、动态的工具,由 Agent 在规划循环中按需调用,并且可以与其他工具组合使用。
普通 RAG 简单、快速,适合 80% 的常规问答;Agentic RAG 复杂、灵活,适合需要多步推理和工具调用的高级场景。在实际企业应用中,两者可以混合使用——简单问题走普通 RAG 路由,复杂问题交由 Agentic RAG 处理。
💡 如果你正在考虑将 Agentic RAG 落地到企业业务中,实在Agent 提供了一个现成的融合方案。它的核心架构正是“TARS 大模型做规划 + ISSUT 屏幕语义理解做感知 + RPA 引擎做执行”,天然支持多步推理、多轮检索和工具调用。借助实在Agent 的可视化工作流编排,你可以快速搭建一个具备 Agentic RAG 能力的智能体,而不需要从零构建 Agent 框架。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。