
















































运输轨迹数据自动归档技巧,流程优化实务
运输轨迹数据自动归档的关键,不只是把文件存起来,而是让轨迹记录能够按时间、车辆、司机和任务快速检索、稳定沉淀,并支持后续分析复用。围绕运输轨迹数据自动归档技巧,可从本地无代码归档、物流系统云端归档、海量数据处理管道三条路径入手,逐步建立高效、可追溯的数据管理机制。
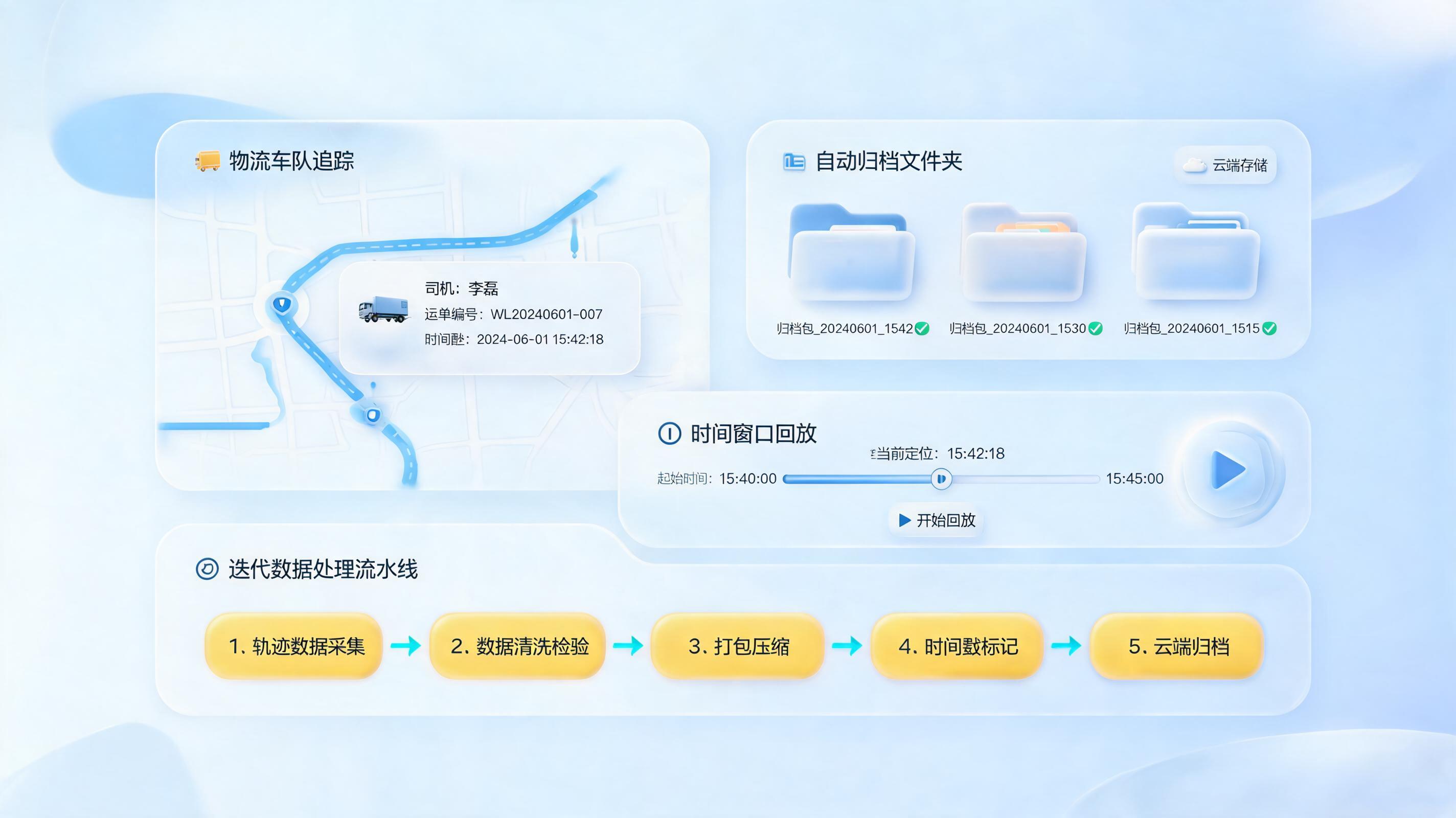
一、为什么运输轨迹数据自动归档越来越重要
运输轨迹数据自动归档直接影响物流企业的数据资产沉淀能力。轨迹文件如果长期散落在个人电脑、手机导出目录或不同项目文件夹中,后续查询某一周、某一车次或某一异常路段时,往往需要人工翻找,耗时高且容易遗漏。
对于需要查询类似10:29:13前后一周这类时间窗口的场景,自动归档的价值尤其明显。只要归档时同步写入时间戳、任务编号、司机信息和车辆标识,历史轨迹回放、异常停留复查、线路复盘都会更高效,这也是物流管理数字化的基础环节。
1.1 自动归档的核心目标
自动归档的目标可以概括为三点:一是减少重复整理,二是提升历史追溯效率,三是为运营分析留存高质量数据。当轨迹数据能持续、标准化进入归档库时,后续才能开展里程统计、停留点分析、异常路线识别等工作。
1.2 归档不等于简单备份
简单备份只解决文件保存问题,而自动归档强调分类、命名、关联、检索。例如,同一趟运输任务的轨迹、电子运单、司机信息、车辆信息如果能够关联存储,管理价值会明显高于零散保存。
二、本地文件场景下的运输轨迹数据自动归档技巧
对于个人用户或小团队,最实用的办法是利用系统自带工具建立轻量级归档流程。以Mac OS的Automator为例,可以把选中文件、压缩打包、移动到归档目录这些重复动作封装为一个服务,在Finder内直接调用。
这种方式适合处理司机或现场人员导出的CSV、GPX、KML等轨迹文件。通过设置服务接收文件或文件夹,并将处理范围限定在Finder,就能在不编写复杂代码的情况下,形成稳定的本地归档动作。
2.1 建议采用时间戳命名规则
本地归档最常见的问题是重名覆盖。更稳妥的做法是在压缩前加入时间戳,形成类似轨迹数据_日期_时间的文件名结构。这样既能避免覆盖,也更方便后续按时间范围定位历史记录。
2.2 归档目录需要固定且分层
归档目录建议按年份、月份、任务类型或车队分层设置。这样做的好处是,哪怕未来再迁移到更复杂的系统,也能保留清晰的数据组织逻辑。若企业正在评估自动化能力平台,也可把这类归档动作纳入统一治理视角,例如参考实在Agent相关页面了解企业级自动化建设思路。
三、企业级运输场景下如何实现轨迹数据云端自动归档
对于多车辆、多司机、多线路的业务场景,企业级方案的重点不是单个文件,而是让轨迹数据与运输业务流程同步沉淀。专业物流管理软件通常会把轨迹采集嵌入行程派遣、实时追踪、任务完成、签收归档的闭环中。
这类机制的优势在于,轨迹数据不是事后补录,而是在任务运行时持续采集并上传。当司机确认到达或签收后,系统即可将完整轨迹、电子运单、车辆信息、司机信息、费用明细自动关联归档到云端数据库。
3.1 为什么云端归档更适合规模化运营
云端归档更适合规模化运营,因为它天然支持按车牌号、司机姓名、运单号、时间段进行检索。对于管理者来说,查询某段历史轨迹不再依赖人工翻找原始文件,而是直接在系统中定位并回放。
3.2 历史轨迹数据的业务价值
归档后的历史轨迹不仅能回溯,还能用于线路拥堵识别、超速行为核查、停留点复盘、司机绩效分析。这些数据如果长期保持完整,就会从记录材料转变为运营优化依据。若企业正在规划更大范围的数字化建设,也可同步关注实在智能官网中的自动化与智能化相关内容。
四、海量运输轨迹数据自动归档后的高效处理技巧
当归档规模持续增大后,新的难点会从保存转向处理。面对每天持续产生的大量轨迹点数据,把全部内容一次性加载进内存会带来明显的性能压力。此时,采用迭代器与链式处理思想,更适合构建稳定的数据处理流程。
迭代器的价值在于按需读取数据,程序每次只处理当前需要的轨迹点,从而降低内存占用。链式处理则把多个步骤串联成管道,让数据按顺序经过读取、展开、过滤、排序、分批等环节,提升整体处理效率与可维护性。
4.1 适合运输轨迹数据的链式流程
一个实用的流程可以包括:逐行读取原始数据、展开嵌套轨迹段、过滤异常点、按时间戳排序、批量输出结果。这种设计非常适合长期运行的数据清洗或分析任务。
4.2 为什么这种方法更利于长期扩展
链式结构便于新增处理节点。例如后续需要加入坐标转换、异常停留识别或模型训练前预处理时,只需在既有流程中插入新步骤,不必整体重写。对于持续积累的历史轨迹库,这种方式更有利于稳定扩展。
五、运输轨迹数据自动归档落地建议清单
第一,先统一命名规则。 无论是本地文件还是系统归档,都应至少包含日期、时间、车辆或任务标识。
第二,再统一归档目录或数据表结构。 目录分层和字段结构越早规范,后续迁移成本越低。
第三,把检索场景提前设计进去。 例如是否要按一周时间窗口、车牌号、司机姓名、运单号筛选,应在归档阶段就预留字段。
第四,区分保存与处理。 归档负责稳定沉淀,分析负责价值挖掘,两者可以连续但不必混为一个动作。
第五,从小场景先跑通。 小团队可先做本地自动化,大团队可直接引入业务系统闭环,再逐步升级处理链路。
六、常见问题解答
6.1 如何快速查询某个具体时间点前后一周的轨迹数据
最有效的方法是在归档时写入标准化时间戳,并建立按时间段检索的目录规则或数据库索引。这样在查询类似10:29:13前后一周的数据时,可以直接按时间窗口过滤,而不必逐个文件打开核对。
6.2 小团队有没有低门槛的归档办法
有。小团队可以优先采用系统自带自动化工具完成文件压缩、重命名和归档目录搬运,先解决重复劳动和文件混乱问题。等轨迹数据量增大后,再迁移到更完整的物流管理系统。
6.3 为什么归档后还需要做链式处理
因为归档解决的是保存和追溯,链式处理解决的是海量数据的清洗与分析效率。两者结合后,轨迹数据才能既存得住,也用得好。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。


