
















































医药研发文献能自动筛选吗?实在Agent重塑文献治理范式
在新药研发的漫长周期中,文献调研与筛选是决定项目成败的基石。然而,面对全球每年以百万篇计的新增学术论文,医药研发文献能自动筛选吗?答案是肯定的。随着大模型技术与超自动化(Hyperautomation)的深度融合,新一代数字员工正将研究员从繁琐的机械搜索中解放出来,转向更高价值的决策与创造工作。
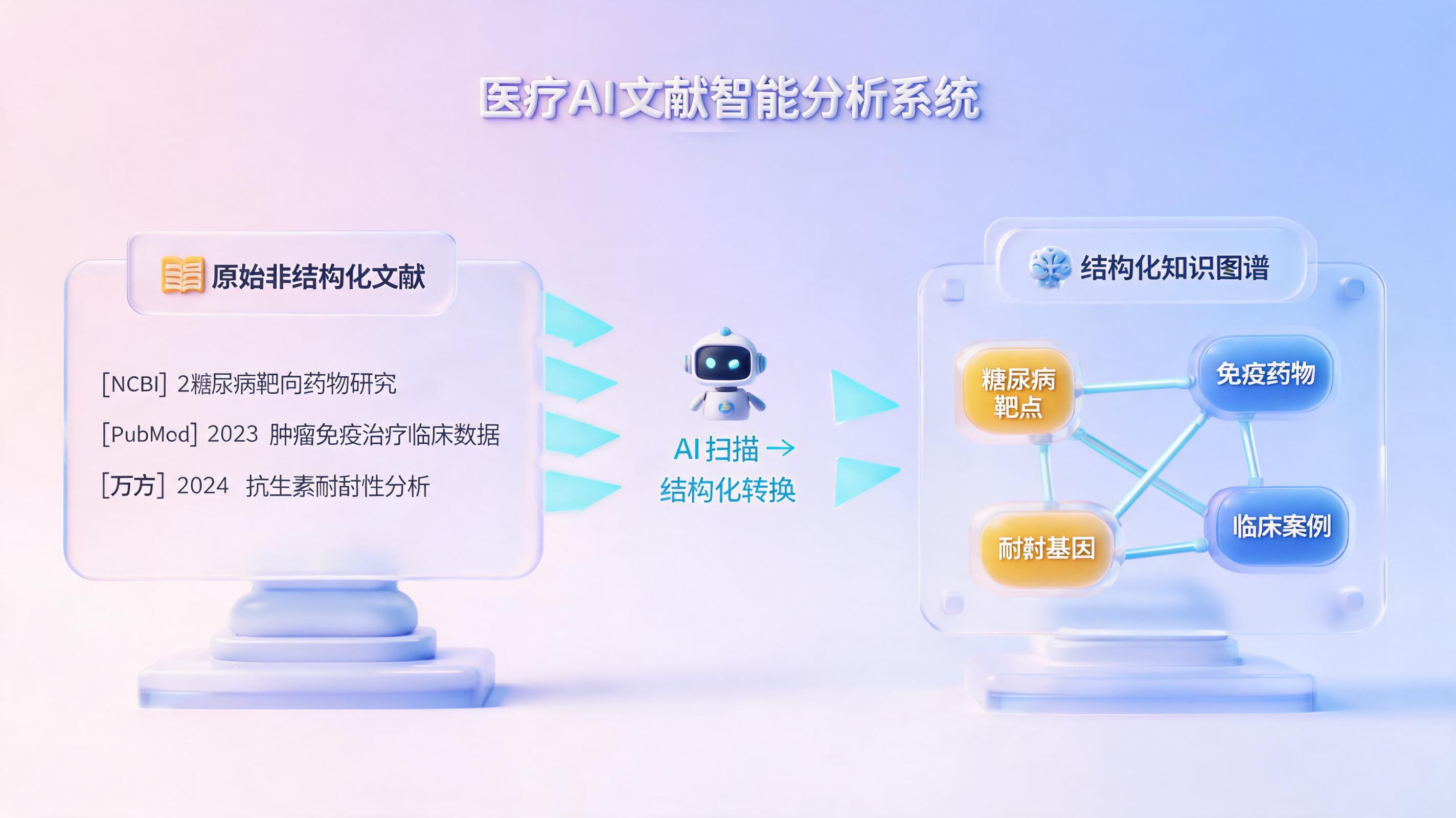
一、 医药文献筛选为何成为研发“瓶颈”?
根据McKinsey的相关研究数据显示,高科技与医药行业的研发人员平均花费约 20% 的时间在信息搜索与收集上。文献筛选的痛点主要体现在以下三个维度:
- 信息过载: NCBI、Papernet等数据库每日更新海量数据,人工依靠关键词检索往往会得到成千上万条低相关结果。
- 理解局限: 传统的检索工具基于关键词匹配,无法理解医药术语的深层语义,导致查准率和查全率难以平衡。
- 数据孤岛: 文献数据分布在多个独立系统与PDF文档中,跨源数据的整合与结构化处理需要耗费极高的人力成本。
二、 实在Agent:从“机械搜索”进化到“语义筛选”
为了解决上述难题,实在Agent 基于自研的AGI大模型与超自动化全栈技术,打造了具备“深度思考”能力的企业级数字员工。它不同于传统RPA的固定规则执行,而是能够像人类专家一样理解复杂的医药业务规则。
1. 长链路业务全闭环
依托大模型的逻辑推理能力,实在Agent可以自主完成从检索策略构建、跨平台文献下载、到全文语义解析与分类的端到端全流程。即使面对长达数百页的非结构化PDF文献,也能实现精准的知识提取。
2. 远程操作与全自主行动
通过首创的远程操作能力,研发人员只需在移动端输入一句指令,Agent即可在本地或云端自动登录专业数据库进行作业,实现“一句指令,全流程交付”。
三、 医药企业真实案例:从14天到30分钟的跨越
某国家级高新技术医药企业在进行临床研究报告编写与相关文献筛选时,曾面临严重的效率瓶颈。该企业医学写作团队 60% 的时间被用于重复性的数据处理与文献比对,单份报告的人工整合周期长达 14天。
引入 实在智能 的解决方案后,该企业构建了医药数字员工阵列。通过AI Agent自动抓取跨源文献,并利用NLP技术进行数据治理与增强:
- 效率跃升: 单次临床文献筛选与报告生成的周期从14天缩短至 30分钟,效率提升了 672倍。
- 人力优化: 由多名专业人员数天的重复劳动,降低为约 5分钟 的人工复核,节省人力成本 99% 以上。
- 质量保障: 数据准确率由95%提升至 99.8% 以上,完美符合NMPA/ICH等监管机构的格式合规要求。
此外,该技术已在更复杂的场景中得到验证。例如在某大型科研项目中,数字员工曾助力处理超过 30万份 极高维度的PDF及扫描件文献,实现了海量非结构化资产的秒级智慧检索。数据及案例来源于实在智能内部客户案例库。
四、 文献治理的未来:构建医药知识图谱
未来的医药文献筛选将不再是碎片化的搜索,而是系统化的知识治理。通过实在Agent,企业可以构建自定义的医药知识图谱,实现对国际组织、政策法规、最新研究机构动态的实时感知。这种“被需要的智能”不仅提高了研发确定性,更在专利合规、配方焕新等场景中展现出巨大潜力。
五、 💡 常见问题解答(FAQ)
Q1:医药文献自动筛选如何保证医学术语的准确性?
实在Agent支持接入DeepSeek、通义千问等主流大模型,并可针对医药行业进行微调。结合企业自有的医学标签体系与知识图谱,能精准识别如“靶向药物”、“缓控释制剂”等专业术语,确保语义理解的专业性与权威性。
Q2:这种自动化方案支持私有化部署吗?
支持。实在智能全栈技术实现 100%自主可控,全面适配国产软硬件与信创环境,支持私有化部署。通过精细化权限隔离与全链路可溯源审计,确保企业的核心研究数据与商业机密绝对安全。
参考资料:2024年Gartner《超自动化技术趋势报告》;McKinsey & Company 2023年医药数字化转型调研数据。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。


