运单怎么自动匹配最优承运商?评分模型与Agent协同
运单怎么自动匹配最优承运商,答案不是先比谁更便宜,而是把线路可达、时效承诺、价格、妥投率、赔付风险、仓网位置、客户等级、平台规则转成统一评分,在出单瞬间给出主推荐和备选承运商;当规则频繁变化、附件非结构化、需要跨系统操作时,单靠固定规则容易失真,加入Agent更容易把分单、校验、回传做成闭环。
一、先把最优定义说清
很多团队一上来就比运价,这是最常见的误区。物流决策里真正的最优,通常是在满足履约门槛前提下的综合最优,而不是单票最低价。
为什么最低价常常不是最优
- 低价但不可达:偏远区、超长件、危险品、冷链等限制,会让低价方案根本不能执行。
- 低价但不稳定:妥投率低、异常件高、签收波动大,后续会放大客服、人力和赔付成本。
- 低价但不适配客户承诺:电商平台、B2B大客户、同城急送,对超时的惩罚远高于节省的运费。
所以,企业更适合把目标函数定义为:先过门槛,再比综合得分。可达性、禁限寄、承诺时效、客户等级属于门槛项;价格、历史表现、异常赔付、结算效率属于评分项。
麦肯锡关于AI赋能供应链的研究常被行业引用:成熟应用可带来5%至15%的物流成本改善、20%至35%的库存优化,并提升服务水平。对承运商匹配来说,价值往往不是单看省了多少运费,而是少错配、少改派、少赔付、少超时。
二、系统到底按什么分,六类指标决定结果
如果想让系统自动而且可解释,至少要把下面六类数据打通。
| 维度 | 关键字段 | 常见来源 | 作用 |
| 基础约束 | 始发地、目的地、重量、体积、件型、品类、温控要求 | OMS、WMS、运单附件 | 先判断能不能发 |
| 成本 | 基础运价、续重、体积重、燃油、偏远附加、上楼费 | 报价表、合同、结算系统 | 避免只看表面单价 |
| 时效 | 承诺揽收、干线时长、派送时长、截单时间 | TMS、承运商接口 | 决定能否守住SLA |
| 服务 | 妥投率、签收时长、丢损率、拒收率、客服响应 | 历史履约库、售后系统 | 衡量稳定性 |
| 风险 | 赔付频次、异常网点、天气、封仓、黑名单 | 风控库、公告、运营监控 | 提前规避高风险线路 |
| 业务策略 | 客户等级、平台考核、利润要求、承运商配额 | CRM、经营策略表 | 让分配符合经营目标 |
一个实用的评分方法
综合得分=可达性门槛通过+成本分+时效分+服务分+风险分+业务策略分。
- 标准快递单:成本权重可更高。
- 高客诉线路:服务分和风险分要上调。
- 平台严考核订单:时效分权重必须高于价格分。
- 大客户专线:先锁定白名单承运商,再在白名单内优化。
这一步的关键不是公式有多复杂,而是字段标准化。比如同一个省份、同一承运商、同一附加费,如果在不同系统里名字不同,自动匹配就会持续失真。
三、从运单到分单,自动匹配的五步闭环
第1步:把运单信息变成可计算数据
系统先从OMS、WMS、邮件、Excel、PDF附件中抽取发货地、收货地、重量、体积、货值、承诺时效、特殊要求等字段,并统一单位与地址标准。
第2步:做硬约束过滤
先剔除不可达、禁运、超尺寸、冷链不支持、结算状态异常的承运商,避免低价方案误入候选集。
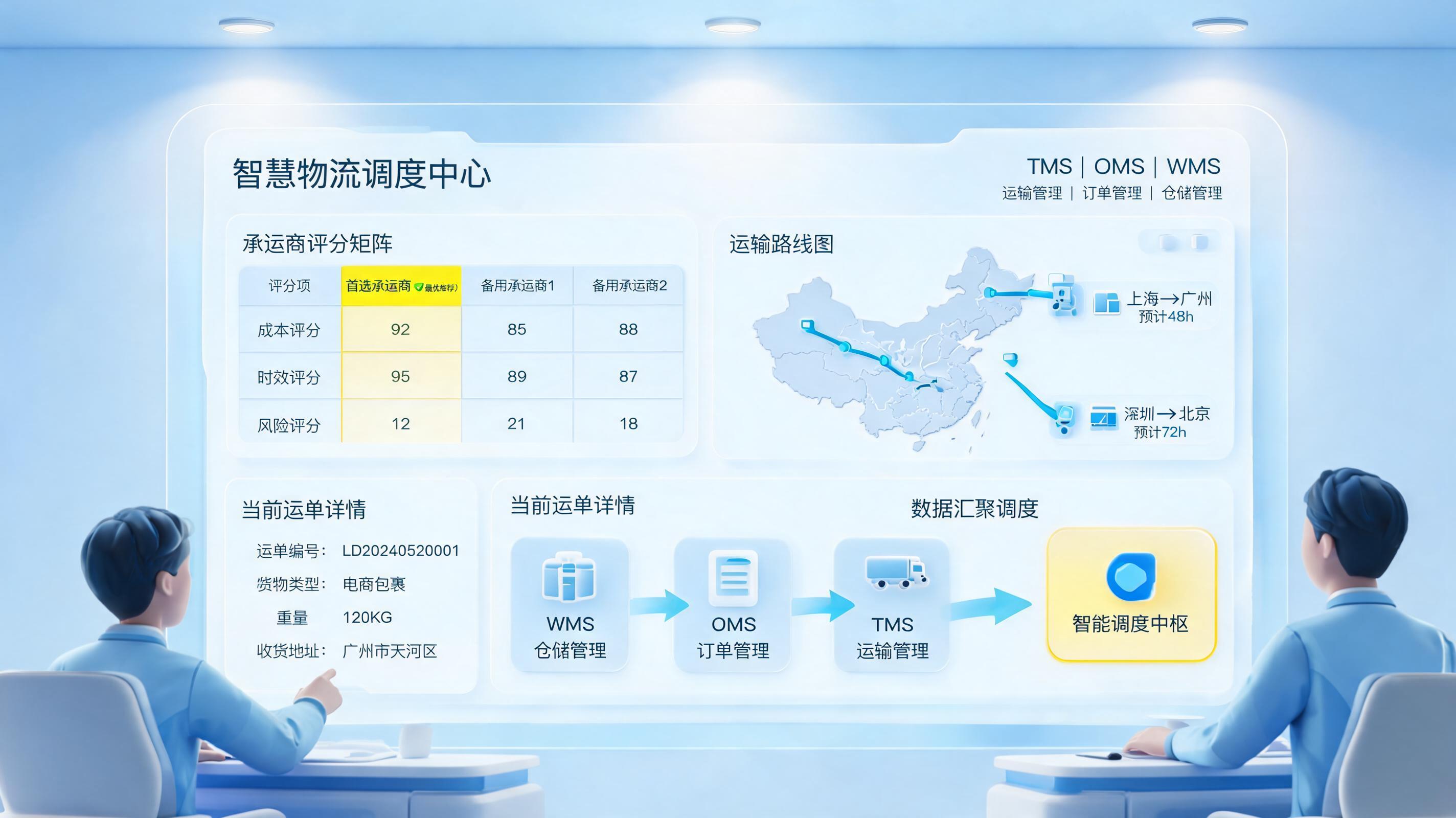
第3步:实时评分并输出主推荐和备选
对剩余承运商计算综合得分,输出1个主推荐+1到2个备选,同时给出原因解释,例如价格低、时效稳、历史妥投高。
第4步:异常单自动分流
对首单新线路、黑名单命中、价格突变、无历史数据、高货值、跨境敏感货等订单,不直接放行,而是进入人工复核池。
第5步:结果回写和持续学习
分配结果回写TMS或ERP,后续再把签收时长、改派、拒收、赔付、客服投诉反哺到评分模型里,形成持续优化。
逻辑树:收单 → 字段标准化 → 过滤不可达承运商 → 计算综合得分 → 输出主推荐与备选 → 回写系统 → 追踪履约结果 → 调整权重。
四、什么场景该上规则,什么场景该上Agent
| 业务场景 | 只用规则引擎 | 规则引擎+Agent |
| 标准件、规则稳定、数据结构化 | 更高效 | 不是必须 |
| 报价表经常变、承运政策靠邮件或PDF通知 | 维护成本高 | 更合适 |
| 需要跨OMS、TMS、WMS、财务系统取数 | 容易断点 | 更稳 |
| 需要给出匹配解释和异常原因 | 可做但僵硬 | 更自然 |
| 业务员通过飞书、钉钉或手机发指令 | 不擅长 | 更适合 |
如果企业只处理标准快递、线路固定、价格月度更新,纯规则已经足够;但遇到邮件委托、Excel报价、PDF公告、临时封仓、客户特殊承诺等非结构化信息时,把规则引擎与实在Agent结合更合适,前者负责硬约束,后者负责读懂附件、跨系统取数、生成解释并推动执行闭环。
上线前建议先准备四张表
- 承运商主数据表:线路、可承接品类、计费方式、接口方式、结算周期。
- 运价与附加费表:续重、体积重、偏远费、燃油、上楼费等。
- 历史履约表现表:妥投率、平均签收时长、赔付率、异常率。
- 策略与例外规则表:客户等级、平台SLA、人工复核阈值、黑白名单。
五、某类物流业务场景下的客户实践
企业级数字员工项目里,已经沉淀出一套可复用闭环:规则智能管理、业务端提单、智能识别、深度校验、结论生成、人工确认。这套方法在物流场景里尤其适合承运商自动匹配,因为它同时解决了规则变化快、附件多、系统多、审计要求高四个难点。
放到运单匹配场景,通常这样映射
- 规则智能管理:把承运商报价、偏远区规则、禁限寄、客户SLA整理成可配置规则库。
- 业务端提单:业务员继续沿用原有TMS或OMS提单,不需要改变习惯。
- 智能识别:自动读取运单附件、地址、品类、重量体积等信息,完成字段抽取与标准化。
- 深度校验:对照规则库与历史履约数据,筛除不可达或高风险承运商。
- 结论生成:输出主推荐承运商、备选承运商和匹配原因。
- 人工确认:高货值、首发线路、命中风险规则的订单进入人工复核,形成审计留痕。
某类物流业务场景下的客户实践显示,这种模式的重点不只是自动分配,而是把原先散落在Excel、邮件、TMS和结算系统中的动作收口为一条可追溯的自动化链路。公开材料未披露具体客户名称与收益数字,但对物流团队最有价值的地方很明确:减少人工查表、减少错配改派、减少超时赔付、提升异常单处理速度。
数据及案例来源于实在智能内部客户案例库
❓六、常见问题
1. 没有足够历史数据,能不能做自动匹配?
可以。第一阶段先用可达性、禁限寄、报价和承诺时效做基础匹配;通常积累8至12周履约数据后,再把妥投率、赔付率、异常率纳入服务分与风险分。
2. 运价和承运政策经常变化,系统会不会很难维护?
关键不是规则多,而是规则有没有配置化。把报价表、附加费、偏远区、限寄规则做成规则库,频繁变动的邮件和PDF由Agent先解析,再由业务确认生效,维护成本会明显下降。
3. 自动匹配会不会把高价值订单分错?
不会完全放开。高货值、冷链、跨境敏感货、首发新线路,应采用自动推荐+人工确认;稳定后再逐步扩大自动放单比例,这比一开始追求全自动更稳。
参考资料:McKinsey,2021年,《AI-enabled supply-chain management》;McKinsey Global Institute,2023年6月,《The economic potential of generative AI: The next productivity frontier》。公开资料发布时间与标题以机构官网页面为准。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。