统计模型资产如何智能管理?闭环治理方法
统计模型资产不是几份算法代码和一堆Excel,而是由模型本体、指标口径、规则逻辑、数据血缘、权限边界、评估记录、应用场景共同组成的复合资产。真正的智能管理,不是把文件归档,而是让模型从‘可保存’升级为可发现、可复用、可审核、可追责、可持续优化。
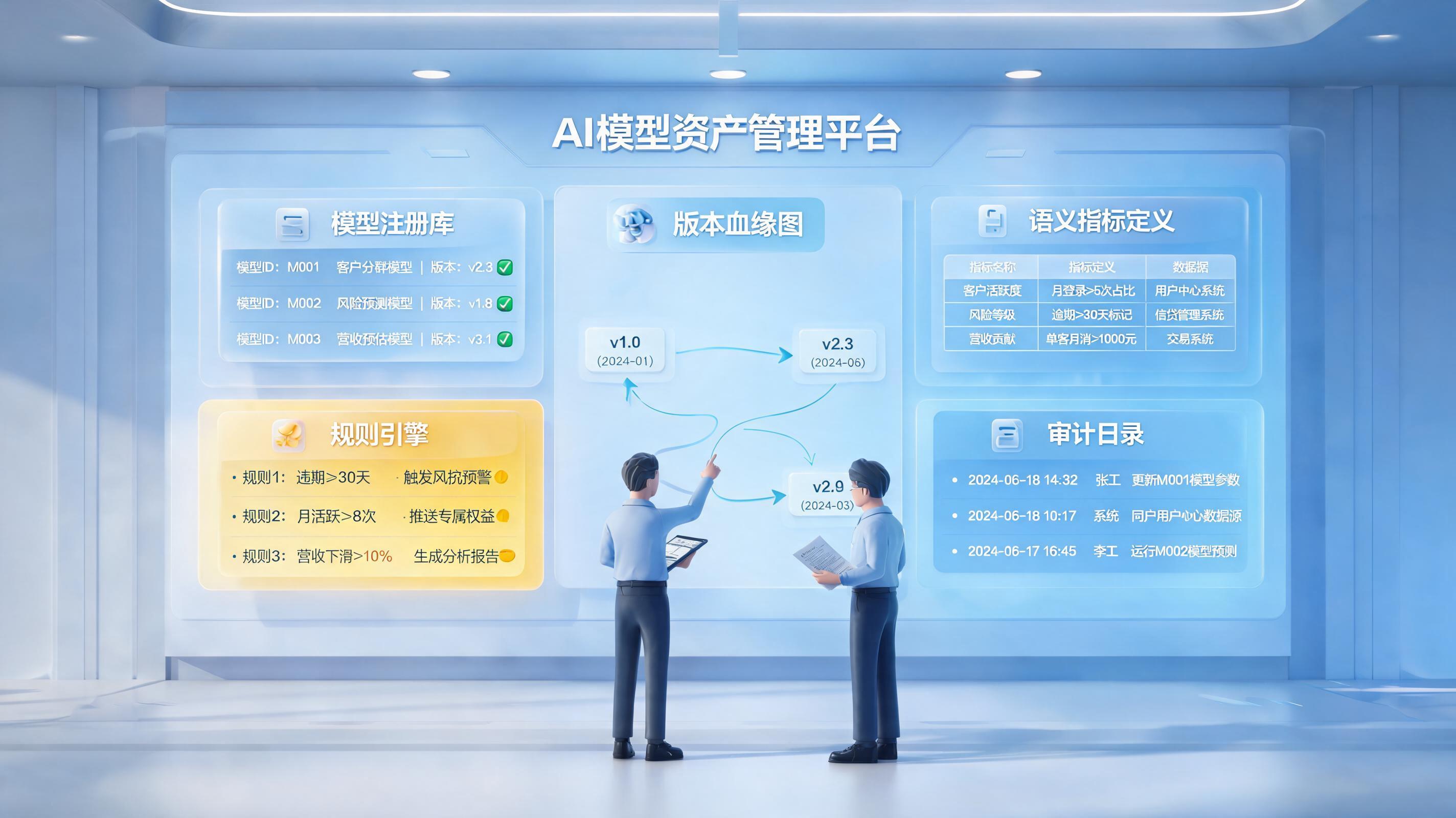
一、先把统计模型资产说清楚
在统计业务里,模型资产至少要同时管理四层内容,否则后续复用一定会失真。
- 模型层:算法代码、参数、脚本、接口、运行环境。
- 语义层:指标定义、样本范围、口径说明、版本说明、适用单位与周期。
- 运行层:调用频次、任务调度、输入输出、异常记录、人工修订痕迹。
- 治理层:责任人、权限、审批、审计日志、退役标准与替代关系。
如果只存‘模型文件’,不存‘模型上下文’,同一个名称的模型就可能在不同科室、不同期次里产生不同解释,最后形成口径冲突。
智能管理是否到位,看这四个问题
- 能否在几分钟内定位某模型的当前有效版本与责任人。
- 能否追溯某次结论由哪份数据、哪套规则、哪次人工复核共同得出。
- 能否把制度文本转成可执行规则,而不再依赖人工反复查阅。
- 能否把复核意见沉淀为下一轮优化素材,而不是停留在聊天记录里。
二、为什么很多单位模型越多,治理越难
难点通常不在建模,而在管理对象被错误地简化成‘文件夹’。常见问题有五类:
- 口径分散:模型、指标说明、制度依据分散在网盘、邮件、OA和Excel里。
- 版本失控:同名模型多份并存,谁是生产版本说不清。
- 规则靠人记:审核条件写在经验里,无法稳定复用。
- 结果不可追溯:结论能看到,形成路径看不到,审计压力大。
- 优化无回流:人工修正没有回灌,模型资产越用越散。
外部环境正在放大这个问题。IDC曾预计全球数据圈到2025年达到175ZB;Gartner曾指出,低质量数据每年给企业造成平均1290万美元损失。对统计部门而言,数据量增长并不自动带来资产价值,只有当口径、规则与日志被统一管理,模型才会真正成为生产资产。
三、智能管理不是上台账,而是跑通五个闭环
| 闭环 | 要管理什么 | 合格标准 |
| 资产闭环 | 统一编号、名称、责任人、场景、版本 | 任何人都能快速找到唯一有效资产 |
| 规则闭环 | 指标口径、校验条件、阈值、例外情形 | 制度可机器执行,不靠个人记忆 |
| 执行闭环 | 调度、调用、跨系统填报、结果输出 | 模型能稳定进入业务流程,不停留在离线分析 |
| 评估闭环 | 准确率、稳定性、异常率、人工修正率 | 知道模型何时该优化、何时该退役 |
| 审计闭环 | 权限、日志、审批、留痕、证据链 | 关键结论可回放、可解释、可追责 |
其中最容易被忽略的是规则闭环。很多模型失效,并不是算法退化,而是业务制度已经变化,模型却没有同步更新。
建议先建立最小治理台账
- 基础信息:资产编号、名称、所属主题、责任部门、责任人。
- 业务信息:统计对象、适用范围、周期、口径依据、输入输出说明。
- 技术信息:脚本位置、依赖环境、接口地址、调度方式、版本历史。
- 治理信息:审批记录、权限范围、审计日志、质量评分、退役状态。
四、统计业务落地,关键不在建模而在执行层
很多统计机构并不缺模型、报表系统和制度文档,真正缺的是把这些资产串起来的执行层。实在Agent更适合承担这件事:一端理解自然语言与制度文本,一端跨系统完成读取、校验、填报、追溯和结果输出,适合把统计模型资产从‘静态存档’升级为‘动态生产力’。
- 知识激活:把指标口径、制度文件、历史审核意见转成可问答、可推理、可执行的知识底座。
- 规则落地:将制度文本解析为可执行规则,减少人工翻制度和口径确认的时间。
- 跨系统操作:在报表系统、OA、Excel、邮件、知识库之间自动流转,降低复制粘贴带来的差错。
- 长期记忆与日志:保留模型调用、参数变更、审核结论与人工修正痕迹,便于复盘和审计。
- 人机协同:常规项自动通过,疑点项高亮给人工复核,避免把统计治理做成黑箱。
Gartner曾判断,到2026年超过80%的企业将把生成式AI API或应用投入生产环境;McKinsey测算,生成式AI每年可带来2.6万亿至4.4万亿美元经济价值。对统计部门而言,最直接的收益往往不是再多训练一个模型,而是让已有模型资产稳定进入业务闭环。
五、某类统计业务场景下的客户实践
当统计模型资产进入实际业务,最常见的对象不是‘训练’,而是‘审核、解释、复核和更新’。某类统计业务场景下的客户实践,采用了与复杂审核场景相同的落地路径:
- 规则智能管理:上传制度文本,由大模型解析并生成可执行规则,完成从‘制度’到‘规则’的转化。
- 业务端沿用原系统:业务人员继续在既有报送或共享系统中提报,不强迫替换原有工作习惯。
- 智能识别与抽取:通过OCR小模型与LLM结合,识别表单、附件和关键字段,自动分类切割。
- 深度校验:调用规则引擎与系统穿透查询,对口径、累计值、缺失项和异常项进行核验。
- 辅助结论生成:系统输出审核辅助结论,标明通过项与疑点项。
- 人工确认闭环:审核人员聚焦疑点项复核,修改意见沉淀回知识库,进入下一轮学习优化。
这套方法的价值,在于把‘模型文件’变成‘可执行审核资产’。在相邻的复杂审核实践中,系统已实现92个业务类型全覆盖、66%初审工作替代率、年处理单据超25万笔,说明只要规则、日志和人工复核机制设计正确,复杂场景也能规模化稳定运行。
数据及案例来源于实在智能内部客户案例库。
六、真正能长期跑下去的管理框架
如果你负责统计模型资产治理,可以按‘三层架构、八码检查’推进,而不是一开始就追求大而全平台。
三层架构
- 底层资产层:模型、数据、规则、知识文档、接口、脚本统一登记。
- 中层控制层:版本、权限、审计、调度、质量评估、预警统一控制。
- 上层运营层:问答检索、审核辅助、自动填报、异常预警、复盘分析统一交付。
八码检查
- 是否有唯一资产编号。
- 是否有清晰口径依据。
- 是否有当前有效版本。
- 是否有明确责任人。
- 是否有调用日志与审计证据。
- 是否有人工复核阈值。
- 是否有质量评估指标。
- 是否有退役与替代标准。
如果这八码有三项以上答不上来,再强的模型也只是高风险文件,而不是可运营资产。
落地时最容易忽略的边界
- 安全边界:统计类资产往往涉及敏感数据,优先考虑权限隔离、私有化部署、全链路审计。
- 组织边界:模型所有权、规则解释权、审批权要分清,避免责任模糊。
- 升级边界:新旧模型切换必须有灰度期,不能一次性替换全部生产逻辑。
💬 常见问题
Q1:统计模型资产管理一定要上专门的MLOps平台吗?
A1:不一定。对多数统计场景,先把台账、规则、日志、权限和复核机制建起来,比单独追求平台名词更重要。平台是承载方式,治理闭环才是核心。
Q2:怎么判断现有模型该优化还是该退役?
A2:看四项指标是否连续恶化:准确率、稳定性、人工修正率、业务解释成本。如果制度口径已变、人工修正长期高位、替代模型更优,就应进入退役评审,而不是继续堆补丁。
Q3:自动化越多,会不会让统计结论变成黑箱?
A3:不会,前提是保留规则来源、执行日志、疑点高亮和人工复核阈值。真正成熟的智能管理不是完全无人,而是让机器处理标准项,让人聚焦例外项。
参考资料:IDC,2018年《The Digitization of the World From Edge to Core》;Gartner,2016年《How to Stop Data Quality Undermining Your Business》;Gartner,2023年关于生成式AI进入生产环境的预测;McKinsey,2023年《The economic potential of generative AI: The next productivity frontier》。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。