门店好评中评差评怎么自动分类统计?零代码AI智能体全流程拆解
门店评价的自动分类统计,在当前数字化运营环境下,已从单纯的人工标注演变为融合自然语言处理、机器学习算法与平台规则的综合技术体系。这项能力直接关联到店铺的线上评分、流量分配、用户信任度乃至实际营收,因此成为商家运营的核心关注点之一。据行业观察,一家日单量过百的门店,每天需要处理数百条来自不同平台的用户评价,人工逐条分类不仅耗时,还极易因主观判断造成偏差,错失关键的改善时机。本文将为你深入拆解如何利用企业级AI智能体,零代码快速搭建一套自动分类与统计体系,并基于此实现业务闭环。
本文您将了解到:
- 🤖 门店评价自动分类的核心技术演进路径
- ⚙️ 主流平台规则对统计模型的影响
- 🛠️ 如何用实在Agent零代码搭建自动分类流程
- 📊 从分类到行动:自动化预警与业务联动
- 🔮 未来趋势:更智能、更精细的评价洞察
🤖 一、 评价自动分类的技术演进:从“查字典”到“读懂反讽”
评价自动分类的底层技术经历了三代演进,每一代都在解决上一代的核心痛点。
1.1 第一代:基于规则的词典匹配
早期的分类方法,如同让机器“查字典”。系统预设正面词库和负面词库,通过计算评论中包含的正负面词汇数量来判定其情感倾向。这种方法实现简单、速度快,但缺陷同样明显:它无法理解语境、反讽和复杂的语义表达。例如,“这速度真是‘快’得让人无语”这样的反讽语句,会被系统误判为好评。
1.2 第二代:统计机器学习模型
为了克服规则引擎的局限,行业引入了支持向量机(SVM)等统计学习模型。其核心思路是将评论文本转化为计算机可理解的数值向量,通过学习大量已标注数据中词汇与情感之间的统计规律,对未知评论进行分类。这种方法准确率远高于规则匹配,但仍高度依赖高质量、大规模的人工标注数据,对新词黑话的适应性较差。
1.3 第三代:大模型驱动的深度语义理解
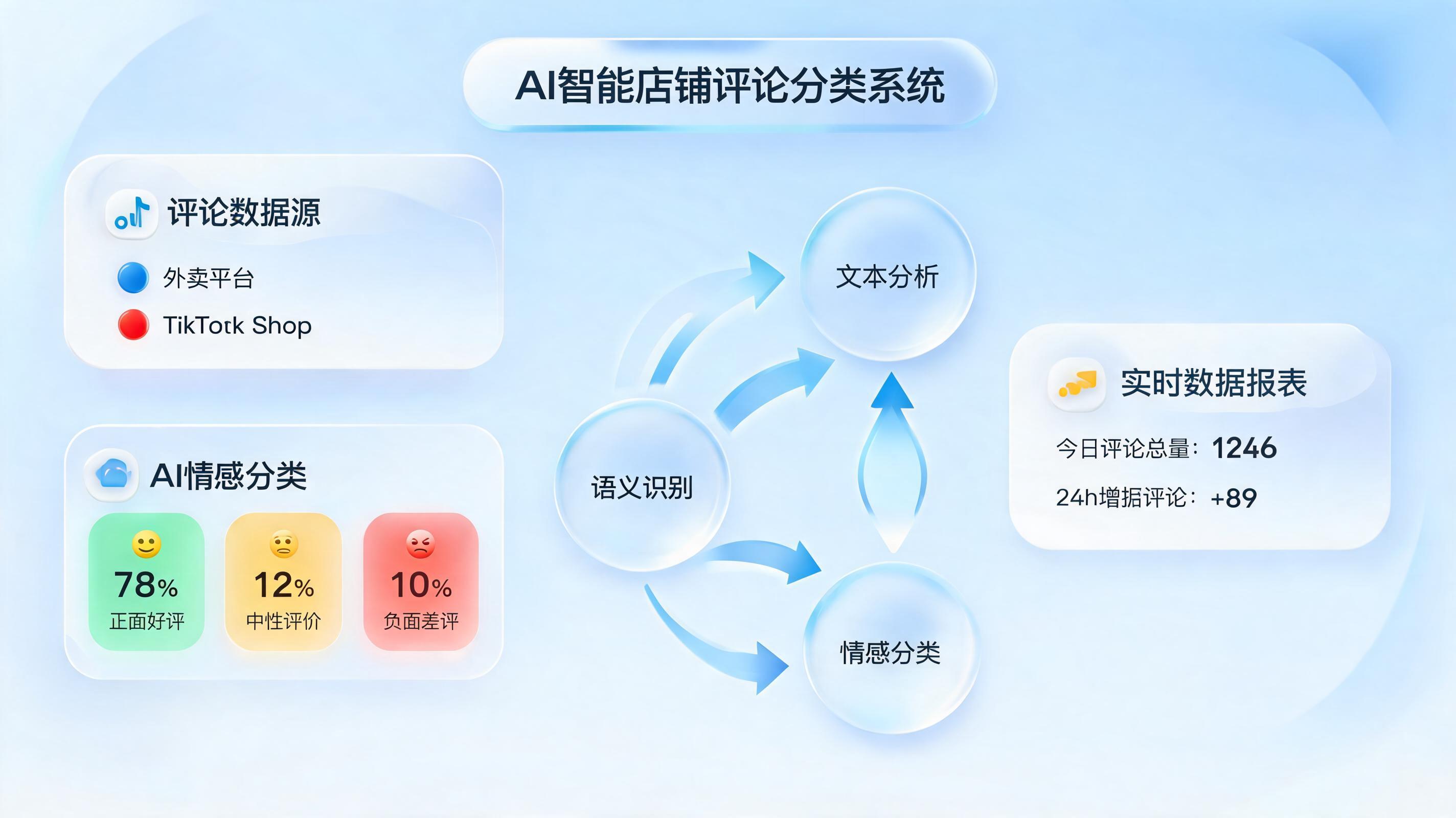
如今,以大语言模型(LLM)为代表的深度学习技术已彻底改变这一领域。基于Transformer架构的预训练模型,展现出强大的零样本学习能力。商家无需再投入巨量人力进行数据标注。例如,你可以直接向模型下达指令:“请按【产品质量】【物流时效】【服务态度】三个维度,判断以下每条评论是正面、负面还是中性”。模型不仅能精准识别“物流快,但屏幕有划痕”这类混合评价中不同维度的情感,还能识别反讽、网络流行语等复杂表达。
实在Agent的价值: 实在Agent内置了强大的大模型调度能力,支持企业在流程中直接调用通义千问、文心一言等主流模型,或使用自研的垂直模型。通过简单的服务节点配置,即可将大模型的语义理解能力无缝嵌入到自动化流程中,对海量评价进行批量化、多维度的情感分析和分类,彻底告别繁琐的人工标注。
⚙️ 二、 主流平台规则解读:你的分类模型为何“失灵”?
理解了技术原理后,必须将其置于各主流平台的规则体系中审视。因为平台的评分机制,直接决定了你的自动分类统计模型该如何校准,以及最终会影响哪些运营指标。
2.1 从“好评率”到“品质负反馈率”的进化
平台规则正从单一指标转向更复杂的综合体系。以某内容社交平台2026年更新的“品质分”规则为例,它被拆解为“综合好评指数”和“品质负反馈率”两部分。后者不仅包括明确的差评,还可能包含退款原因、客服投诉等隐含负面信号。这意味着,即使一个买家没有写差评,但若因质量问题退款,这笔订单仍可能被计入“负反馈”,拉低店铺分。
2.2 精细化考核:TikTok Shop的差评分类
TikTok Shop将店铺差评细分为商品差评、物流差评、消费者体感差评等。在计算“店铺商责差评率”时,平台会剔除物流和消费者体感差评,只聚焦于商家核心责任的商品质量问题。这种官方的分类统计方式,本身就为商家指明了优先级。
实在Agent的价值: 实在Agent的非结构化数据处理能力,能完美应对这种精细化分析需求。通过构建包含“物流”、“产品”、“服务”等维度的知识库,智能体可以自动将差评按责任归属打标并统计。管理者无需手动翻阅,每天定时通过机器人收到一份结构化报表,清晰了解哪个环节出了问题,从而精准施策。
🛠️ 三、 从零搭建:用实在Agent实现自动分类统计
理论说再多,不如亲手搭建一次。以“某连锁饮品店自动分析各大外卖平台评论”为例,我们可以利用实在Agent的零代码智能体编排能力,在可视化的画布上轻松拖拽出如下流程。
3.1 流程设计:采集、分类与落库
- 触发与采集:设置一个定时触发器,如每天凌晨2点,自动调用外卖平台开放API接口,拉取前一日所有新增评论。
- 文本预处理:使用一个基础脚本节点,将拉取的不规则数据进行清洗,统一格式,并过滤掉纯表情或无意义内容。
- 核心分类处理:这是关键一步,我们将引入AI能力。我们在实在Agent的流程设计器中,可以选择调用“大模型服务”节点。在该节点的配置区域,设置系统提示词:“你是一个专业的客户体验分析师。请对以下用户评论从【口感】【包装】【配送速度】【整体满意度】四个维度进行情感判断,输出结果为‘正面’、‘负面’或‘未提及’”。
- 分类入库:将大模型返回的结构化结果与原评论文本一同写入数据库的“评价分析结果表”。
- 结果推送与统计:利用一个条件分支和报表生成插件。如果某维度出现连续3条以上“负面”,则自动发送预警邮件或即时消息给店长。每周自动生成一份多维度评价分析报告,发送至运营总监邮箱。
实在Agent的核心优势在此体现:
- 零代码编排:整个流程无需编写一行代码,业务人员通过拖拽“触发器”、“循环”、“大模型”、“数据写入”等节点即可完成。
- 卓越中心协同:通过卓越中心,店长可以直接提交“我想看到近一周包装问题的差评趋势”的需求,IT负责人评估后,可将已开发好的此流程分享给所有门店店长使用,形成从需求发现到价值复用的全套闭环。
- 环境与插件支持:在实在Agent的【设置中心】-【工具插件】中,可轻松配置连接各大平台的HTTP插件和数据库连接器,确保流程在不同网络环境下稳定运行。
3.2 灵活驾驭复杂逻辑:条件分支与服务节点
在自动分类流程中,我们难免会遇到复杂的业务规则。比如,某集团在不同地区有不同门店,对差评的容忍度各异。此时,实在Agent的条件分支功能就派上了用场。
- 场景举例:在“结果推送”环节,我们可以设置条件分支。满足条件1(门店=北京旗舰店 AND 差评数>3),则立即通知大区经理;否则进入条件2(门店=普通分店 AND 差评数>5),则通知门店店长。条件分支有严格的优先级,一旦满足条件1,就不会再进入条件2,确保了流程逻辑的清晰可控。
同时,企业通常已有现成的IT系统。实在Agent中的服务节点允许我们在流程中直接调用内部API。例如,无需将评论数据导出再导入,直接调用BI系统的一个内部接口,将分析好的评价分类数据实时推送到管理驾驶舱的大屏上。
📊 四、 从分类到行动:构建自动化预警与业务联动闭环
自动分类统计的终点不是报表,而是驱动行动。
4.1 建立基于分类的预警机制
利用实在Agent的条件分支,你可以设置多维度的预警规则。当系统通过大模型自动识别出某新品出现“口感不佳”的集中差评时,可立即触发预警。系统会调用通知服务,向供应链、质检、客服等部门的关键人员发送邮件或消息,同时自动发起一个退货抽检流程的工单。这种从“识别”到“预警”再到“响应”的自动化闭环,是智能体区别于传统数据分析工具的核心价值。
4.2 深入洞察与产品迭代
持续累积的结构化评价数据是一座金矿。你可以定期分析“中评”数据,因为这往往是用户摇摆不定、包含建设性意见的地方。例如,通过分析发现大量中评提及“希望提供少糖选项”,这便是一个清晰的产品迭代信号。
实在Agent的价值: 凭借其强大的非结构化数据处理和知识库检索能力,实在Agent可以连接企业内部的研发知识库。当它发现某个痛点高频出现时,能自动检索知识库中的产品工艺文档,为研发人员提供可能的改进方案参考,将前端反馈与后端研发直接联通。
💎 结语
门店评价的自动分类统计,已从锦上添花的辅助工具,进化为关乎企业竞争力的核心数据资产。通过引入以大模型为驱动的企业级AI智能体,企业不仅能实现从采集到预警的全流程自动化,更能穿透文本表面,挖掘出驱动产品创新和服务升级的深层洞察。这并非替代人工,而是将人从低效的重复劳动中解放出来,去专注于只有人能完成的策略制定和高价值沟通。如果你想立即体验如何零代码搭建这样一套智能体流程,不妨从实在Agent开始,亲眼见证技术如何重塑运营效率。
❓ 常见问题解答(FAQs)
- Q:对于单个门店,评价基数不大,有必要上自动化系统吗?
A:非常有必要。评价规模小,但涉及的平台可能不止一个,且中评、差评的每一条反馈都异常宝贵。自动化系统能帮你节省时间,实现多平台聚合统计,更重要的是它能提供标准化的分析维度,避免人工判断的主观偏差,帮助你系统性发现问题。 - Q:如何应对同行或者职业差评师的恶意攻击?
A:可以利用实在Agent搭建一个“恶意评价预警”流程。通过条件分支,设置规则监测短时间内出现的、来自相似账号的、内容模糊的差评。一旦触发阈值,流程可自动收集证据、截图存档,并调用邮件服务向平台官方提交申诉材料,大大提高反制效率。 - Q:自动分类的结果准确率能达到100%吗?
A:不能,也没必要追求100%。复杂的人类语言,尤其包含反讽、行业黑话时,任何AI模型都难以保证绝对完美。企业级应用的核心目标是达到“足够好”的水平(如95%以上),以显著降低人工复核成本。关键在于建立“机器自动分类+人工抽检修正”的反馈闭环,让模型在业务流程中持续学习、自我进化。 - Q:选用不同的大模型,对分类统计的成本和效果影响大吗?
A:影响很大。不同大模型在语义理解能力、推理成本和响应速度上差异显著。实在Agent支持多模型调度,你可以为常规的简单好评分类配置一个响应快、成本低的模型,而对需要深度理解反讽和复杂语境的中差评,则调度一个能力更强的模型,实现效果与成本的极致平衡。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。