















































产品评论关键词怎么自动提取?AI智能体实现竞品分析全流程自动化的核心拆解
你是否也遇到过这样的困境:市场部需要分析数千条用户评论,提炼产品优劣势,但人工逐条阅读不仅耗时耗力,还容易遗漏关键信息。据Gartner预测,到2025年,超过70%的企业将利用AI驱动的文本分析来指导产品迭代。本文将为你拆解产品评论关键词自动提取的成熟技术路径,并展示如何借助企业级AI智能体打通从数据采集到洞察输出的完整自动化链路。
- 技术路径速览:从预训练模型到专用分类器的四种主流方案
- 行业场景落地:电商、手机、SaaS产品评论的真实应用
- 智能体全流程自动化:如何让数据采集、情感分析、关键词抽取实现无人值守
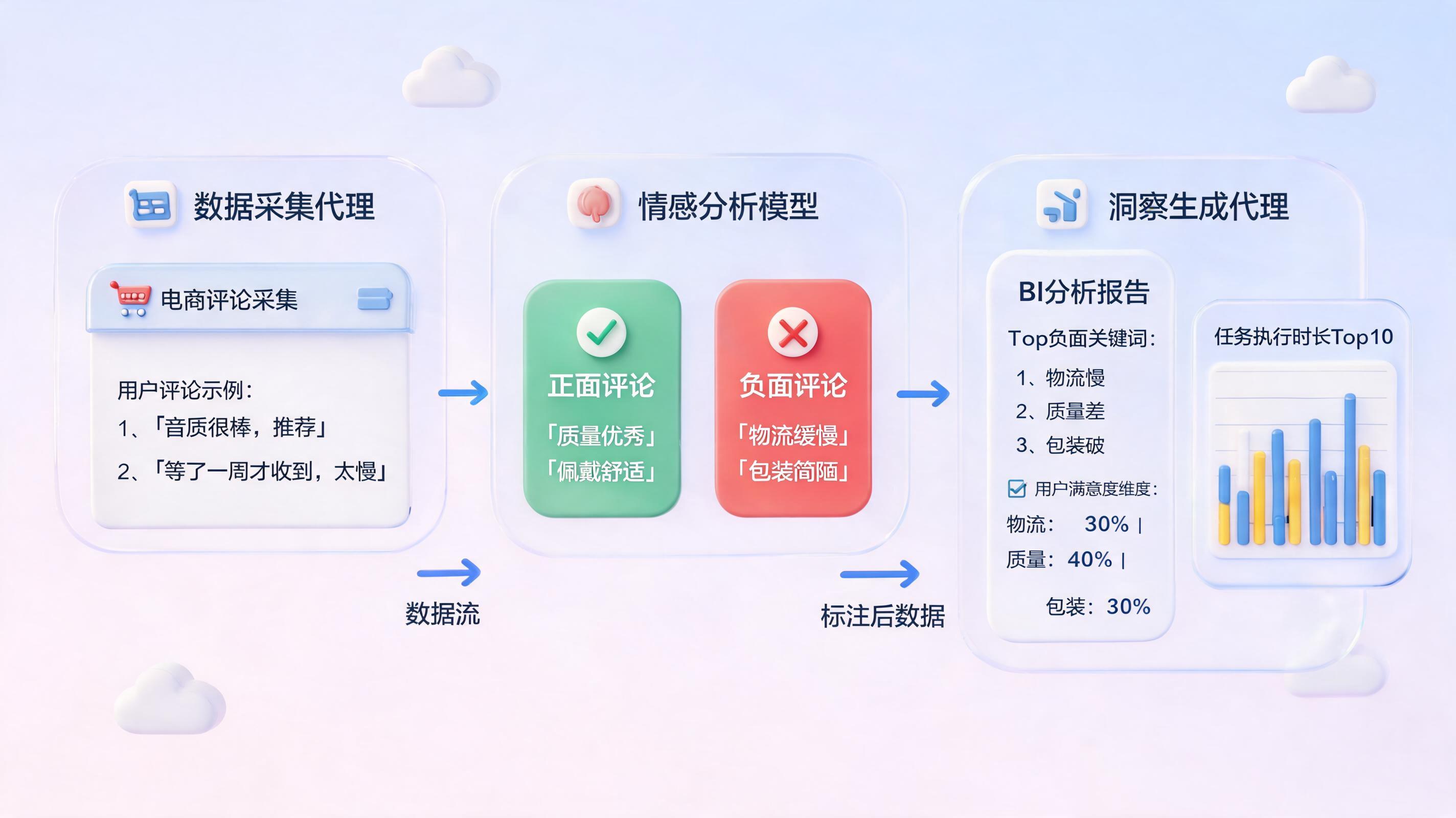
I. 产品评论关键词自动提取的核心价值与基础原理
1.1 为什么需要自动提取:从噪音到洞察的跨越
产品评论中蕴含大量用户真实观点,但文本非结构化、表达随意性强。关键词自动提取的本质,就是让机器精准定位并抽取出能代表用户关注焦点、情感倾向的短语。例如,从“手机续航一般,但屏幕显示效果很棒”中提取出正面关键词“屏幕显示效果”和负面关键词“续航”。这一能力直接驱动竞品分析、用户体验优化、舆情监控等业务场景。
1.2 关键技术组件一览
实现自动提取的现代技术栈通常包含:
- 情感分类模型:判断评论整体是正向还是负向。
- 命名实体/属性抽取:定位产品具体特征词,如“摄像头”、“电池续航”。
- 主题建模:无监督地发现评论中隐藏的讨论主题。
- 规则引擎:结合业务知识,精细化匹配“属性-评价”对。
- 自动化流程调度:整合爬虫、API调用、结果入库等环节。
II. 四种主流技术路径详解:从轻量到高精度的方案矩阵
2.1 预训练情感模型 + 关键词粗筛:极速上手的入口
这是门槛最低的方案。直接调用HuggingFace等平台的预训练情感模型(如twitter-roberta-base-sentiment)对评论打上正面、负面标签,再对正负面评论分别抽取高频名词短语。例如,实在Agent设计器中,可零代码集成此类模型API,自动完成批量评论的情感标注和关键词初步统计,并输出结构化的“优点列表”和“缺点列表”。适合初创公司或需快速出结果的场景。
2.2 无监督主题建模:发现隐藏的用户关注点
当评论数据量达到数万级别,评论中可能会出现意料之外的讨论热点。BERTopic技术可自动将评论按语义聚类成多个主题,并给出每个主题的核心关键词。结合每条评论的情感得分,系统自动判定主题是正面还是负面。例如,在实在Agent运营管理平台中,可通过“效益分析”模块加载BERTopic流程,内嵌多模型调度,一键生成“高频错误任务TOP10”式样的主题关键词报告,帮助产品经理发现“物流包装损坏”这类易忽略的吐槽点。
2.3 规则增强流水线:高业务可控性的选择
对于需要精确召回固定产品属性的场景,采用“NER/依存句法+规则模板”的组合效果更佳。例如,预设规则“<摄像头>+很+<清晰>”可以准确提取出“摄像头_清晰”这样的标准化配对。该方法可解释性强,但需要维护领域词库。在实在RPA控制器中,可建立标签管理规则,将提取出的关键词自动打标、归类,并通过自定义标签在后续任务中快速筛选对应流程,实现过滤与精准派单。
2.4 对比学习微调专用分类器:极致精度的定制之道
如果企业拥有足量标注数据,微调基于对比学习的分类器能获得最佳效果。模型不仅能判断评论片段的正负面,还能区分同一属性下的细粒度缺点,如“电池容量小”和“充电慢”。对于追求极致竞品分析精度的大厂,这种方法值得投入。实在Agent支持私有化部署和信创适配,允许企业将微调后的私有模型安全地嵌入到自动化流水线中,实现高精度、高安全的领域定制分析。
III. 从技术到落地:AI智能体如何实现全流程无人值守
3.1 多智能体协同架构:打通采集、分析、报告输出
一个完整的自动化评论分析系统需要多个AI智能体协作:
- 数据采集Agent:模拟浏览器操作,自动登录电商后台或社交媒体API,抓取用户评论并处理验证码。
- 解析与分类Agent:对图文评论进行OCR和实体抽取,调用情感模型进行极性标注。
- 洞察生成Agent:整合统计结果,自动生成包含“高频缺点TOP10”、“用户满意维度分布”的BI报告。实在Agent的数字员工可完美实现这一分层架构,通过低代码拖拽即可配置各智能体的任务触发条件、异常重试策略,并支持“任务运行时长TOP10”等监控看板,实现真正无人值守。
3.2 实在Agent在典型场景的应用足迹
- 财务场景:自动提取发票评论(如税局反馈)中的高频错误原因,关联“失败原因占比”仪表板,快速定位审核痛点。
- IT运维:从工单评论中抽取“等待时长最多”的关键技术词,驱动“任务等待时长TOP10”分析,优化服务知识库。
- 电商运营:对接淘宝
item_review接口,每日自动采集竞品评论,提取卖点关键词,生成微信群简报。实在RPA机器人与Tars-Agent智能体联动,既保证接口合规性,又实现零代码的多步骤编排。
IV. 未来趋势与行动建议
评论关键词提取正朝着处理多模态数据(图片、视频中的评价)、实时流式分析和因果推理方向发展。对于企业而言,当下最务实的路径是选择一个可扩展的平台,先从预训练模型快速验证价值,再逐步引入定制化方案。实在Agent系列产品提供从设计器到控制器、从RPA机器人到AI智能体的无缝融合,支持私有化部署和信创环境,帮助企业将评论洞察能力转变为持续的数字化护城河。
常见问题解答(FAQs)
Q:产品评论关键词提取需要自己训练模型吗?
A:不一定。推荐先用HuggingFace等平台的预训练模型快速启动,实在Agent支持零代码调用这些API;当需处理特殊领域或要求高精度时,再用您自己的数据微调,实在Tars-Agent能帮您无缝集成微调后的专属模型。
Q:如何保证提取的关键词能准确反映产品优缺点?
A:结合情感分析是关键,先用模型区分正负面评论,再分别抽取关键词,就能天然分离优点和缺点。在实在Agent运营平台,还能通过自定义标签系统对提取结果二次筛选,进一步保证准确率。
Q:需要多少数据才能出有效的结果?
A:对于无监督方案,通常5000条以上评论能发现稳定主题;对于预训练方案,几百条也能给出初步指引。实在Agent的控制台提供任务执行看板,帮您监控数据量和分析效率,逐步优化模型。
Q:这些自动化会不会触碰各大平台的反爬措施?
A:只要遵循平台API规范(如淘宝开放平台的item_review接口)并合理控制请求频率,风险极低。实在手机机器人或RPA可通过模拟人工操作、延时随机化等策略合规采集,保障业务流程的长期稳定运行。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。
