















































外地分行数据统一整合方法:一周落地路径
外地分行数据统一整合方法的关键,不是简单把各地表格拼在一起,而是用统一标准、集中汇聚、分步校验、持续增量的方式,快速形成总部可用的一本账。对于跨区域经营的银行、金融机构和大型集团来说,这项工作直接影响战略决策、风险管控、经营分析和分支协同效率。
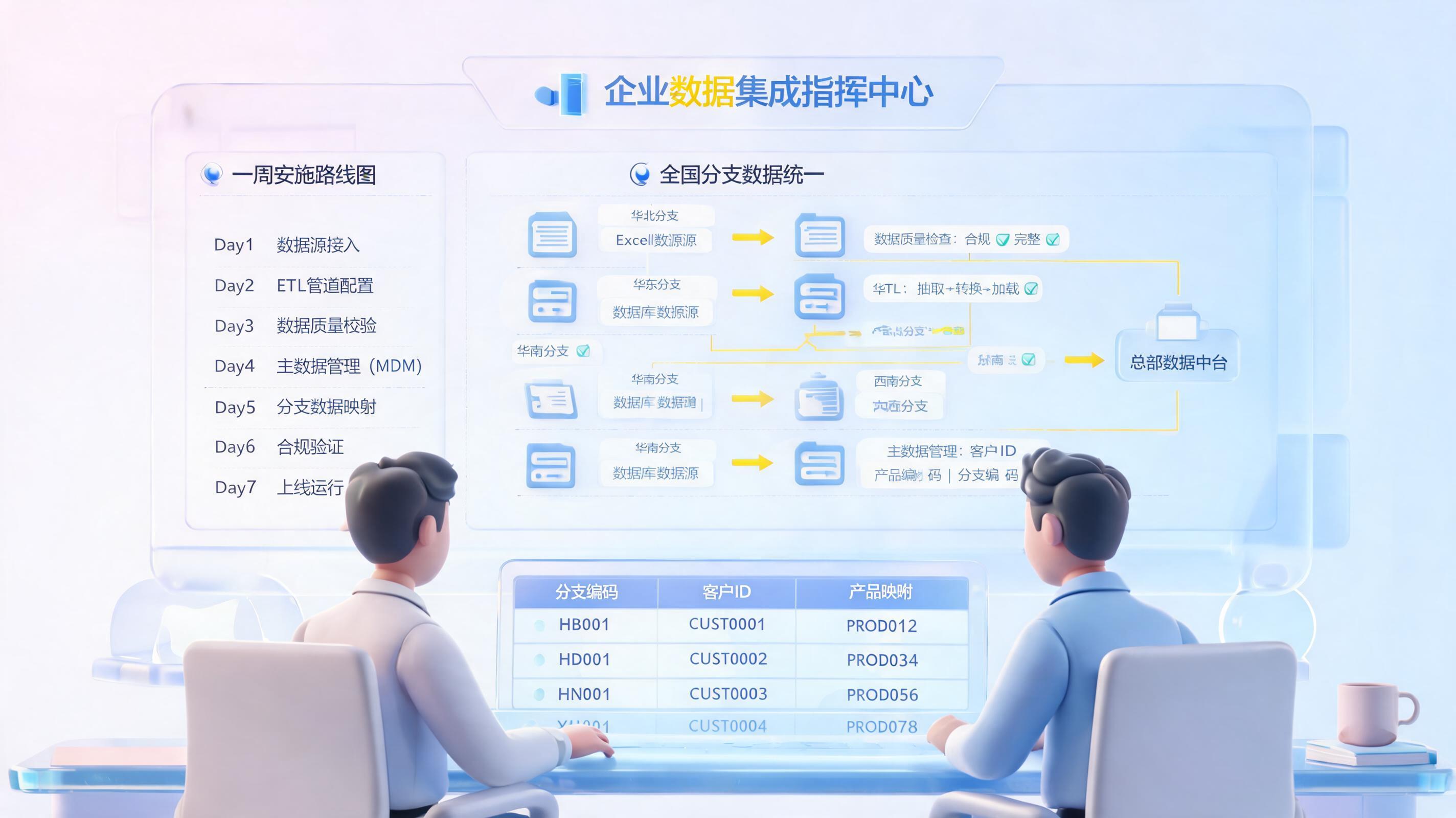
一、先明确目标:外地分行数据统一整合到底要解决什么
外地分行数据统一整合方法的第一步,是把业务目标定义清楚。总部通常并不缺数据,真正缺的是口径一致、时效稳定、可追溯、可复用的数据结果。只有先明确整合后的使用场景,如经营分析、风险监测、财务核算、客户画像,后续的字段标准、同步频率和质量规则才有依据。
从实践看,外地分行数据整合通常面临三类难题:一是数据源分散,数据库、Excel、CSV、日志、文档并存;二是口径不统一,同一客户、产品、机构在不同分行命名不同;三是责任边界不清,总部与分行都觉得数据问题不在自己。要在一周内推进,必须先把这三件事说透。
1.1 统一目标比统一技术更重要
整合项目常见误区是先上工具,后补标准。更稳妥的做法是先确定总部要看到什么、分行要上报什么、哪些字段必须统一、哪些字段允许保留本地差异。这样可以避免后续反复返工。
1.2 一本账的前提是一数一源
如果同一个客户编号、产品代码、会计科目在多个系统里各有一套解释,再好的平台也难以输出可信结果。因此,外地分行数据统一整合方法必须坚持数据源头唯一、标准统一、权责清晰的原则。
二、搭建统一底座:数据中心与治理体系同步建设
高效整合的核心,是建立一个企业级的数据中心或数据中台,作为所有分行数据的唯一汇聚点。这个汇聚点需要兼容多种数据库类型,如Oracle、MySQL、SQL Server,同时支持结构化表格、非结构化文档和日志文件的接入。
技术上,可以采用ETL或数据集成平台,按配置方式定义从分行源系统到中心仓库的数据同步任务。这里最重要的是支持增量抽取,避免每次全量同步带来的网络和计算开销。这样既有利于在较短周期内完成首次整合,也能为后续每日增量同步打下基础。
2.1 数据治理要有明确组织机制
总部牵头建立数据治理委员会或专项项目组,是推进速度的保障。总部负责平台、标准、策略和监督,各分行负责本地数据的准确性、完整性和按时上报。技术方案如果没有组织机制支撑,往往很难真正落地。
2.2 数据质量必须在接入环节前置
格式校验、逻辑校验、重复识别和异常告警,应该在数据接入时自动完成。只有把脏数据拦在仓库外,后续的报表、分析和决策才能稳定。对异常数据进行标记和回溯,是形成闭环管理的关键动作。
三、标准化落地:盘点、映射、清洗、核算四步走
外地分行数据统一整合方法最实操的部分,是建立标准化处理流程。可执行路径通常包括数据资产盘点、统一编码规范、清洗转换、差异分析与统一核算四个环节,这也是把多源异构数据变成统一经营视图的核心过程。
3.1 先做数据资产盘点
要先回答四个问题:各分行拥有哪些数据、存储在哪里、结构如何、质量怎样。自动化扫描配合人工确认,是较为稳妥的盘点方式。这一步完成后,项目才真正进入可控状态。
3.2 再做字段映射和数据字典
统一客户编号、产品代码、机构代码、会计科目,是解决一数多源问题的核心。比如客户名称存在简写、错别字、命名差异时,需要先建立统一规则,再做标准化转换,否则不同分行的数据无法准确关联。
3.3 清洗规则要可复用、可追溯
在清洗阶段,常见动作包括字段类型转换、单位换算、日期格式统一、空值处理和重复记录识别。对收入金额、订单金额等核心字段,还要建立差异分析机制,追溯是录入错误、理解偏差,还是系统计算逻辑不同,再决定修正数据还是调整映射规则。
四、一周推进计划:从试点接入到统一分发
如果目标是尽快见效,可以采用敏捷推进方式,把整合项目拆成日程明确的小迭代。一个可参考的节奏是:第1天完成网络连通与数据源接入测试,第2天抽取试点分行数据,第3天完成质量评估与清洗,第4天进行核心业务数据转换与加载,第5天开展全量校验与报表验证,最后两天处理问题并优化规则。
这种分阶段推进方式的价值,在于快速发现问题、快速修正规则,而不是把风险堆到最后一次性爆发。对总部而言,这也是最容易向管理层证明阶段性成果的路径。
4.1 文件型数据可用脚本批量整合
当分行主要上报Excel、CSV等文件时,Pandas是高效方案。利用glob配合pd.concat可批量合并同构文件;对异构文件,则需要先建立字段映射字典,再通过rename统一字段名。清洗时可使用drop_duplicates()去重、fillna()补空、astype()改类型,并借助str.replace()和pd.to_numeric()处理金额中的货币符号、逗号与空格。
4.2 非技术人员可借助智能工具降低门槛
对于临时性、多部门的数据整合任务,具备自然语言理解能力的AI工具可以帮助业务人员更快完成合并、去重、异常值过滤和分组汇总。但无论采用何种工具,前提都是在授权、合规的企业环境中处理自有数据,并遵守相关数据安全要求。
五、从整合到赋能:让总部看得到,让分行用得上
数据整合的最终价值,不是把数据搬到总部,而是形成数据上行整合、能力下行赋能的闭环。一个成熟做法,是在总部建立全局主数据管理机制,记录客户唯一标识及其在各分行的关联信息,再通过权限控制实现安全共享。
整合后的数据还可以通过API或统一服务能力回传分行业务系统,让一线人员在授权范围内获得完整客户画像和历史记录,提升服务效率与客户体验。这种模式兼顾了集中管控、分支协同、数据安全和业务可用性。
如果企业希望进一步把跨系统数据采集、规则执行和流程协同自动化,可以在合规前提下评估实在Agent这类智能体工具,帮助标准流程更稳定地落地。对于希望持续推进数字化治理的团队,也可以关注实在智能发布的相关企业自动化实践。
六、常见问题 FAQ
Q1:外地分行数据统一整合方法为什么总是推进缓慢?
根本原因通常不是工具不足,而是标准不统一、责任不清晰、质量问题后置。先统一目标口径,再建立数据字典、质量规则和总部分行职责分工,推进效率会明显提升。
Q2:一周内完成整合,现实吗?
现实,但前提是目标聚焦。更可行的方式是先完成试点分行和核心字段的整合,优先打通经营分析或财务核算必需数据,再逐步扩展到更多分行和更多主题域。
Q3:Excel和数据库混合场景怎么做?
可以采用双轨并行方式处理:数据库数据通过ETL做增量同步,Excel和CSV文件通过标准模板、字段映射和脚本清洗后再统一入仓。关键不是来源形式,而是最终口径必须一致。
Q4:怎样保证整合后数据可持续使用?
需要把一次性项目变成持续机制,包括增量同步策略、异常告警、数据质量看板、字段变更管理和权限审计。只有形成制度化运营,统一整合成果才不会在几周后失效。
总结来看,外地分行数据统一整合方法的本质,是以治理先行、架构承载、规则落地、迭代推进为主线,把分散的数据资产变成可持续服务业务的统一能力。对总部而言,这既是效率工程,也是管理工程。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。


