怎么自动化比对案卷图文信息?识别校验一体化
案卷图文信息自动比对,本质上不是单纯上OCR,而是把扫描页、现场照片、录入字段、业务系统记录放到同一证据坐标系里,完成识别、切割、字段映射、规则校验、疑点输出、人工复核六步闭环;只有图像理解与业务规则一起做,才能真正减少漏审、错审与返工。

一、先把案卷拆成可比对的4类对象
1. 图像层
- 扫描页、拍照件、附件图片、印章、签名、手写批注、表格截图。
- 先做去噪、纠偏、分页、重页检测、缺页检测,否则后面的识别结果会持续放大误差。
2. 文本层
- 对印刷体、表格、半结构化表单做OCR与版面分析。
- 把案号、姓名、日期、金额、地址、文号、证据名称等抽成可计算字段。
3. 结构化层
- 把OCR结果与业务系统字段、台账、历史案卷目录做统一映射。
- 重点解决同义字段问题,例如当事人姓名与申请人姓名、立案日期与受理日期。
4. 证据关系层
- 自动比对的核心不是两张图像像不像,而是同一事实在不同材料里是否一致。
- 最常见的关系包括:同人同号、时间先后、金额一致、附件与正文互证、签章存在、页码连续、图片内容与录入文本一致。
如果任务定义不清,模型再强也只能输出漂亮但不可审计的答案。真正可落地的做法,是先把案卷审核拆成一组可验证的小检查项。
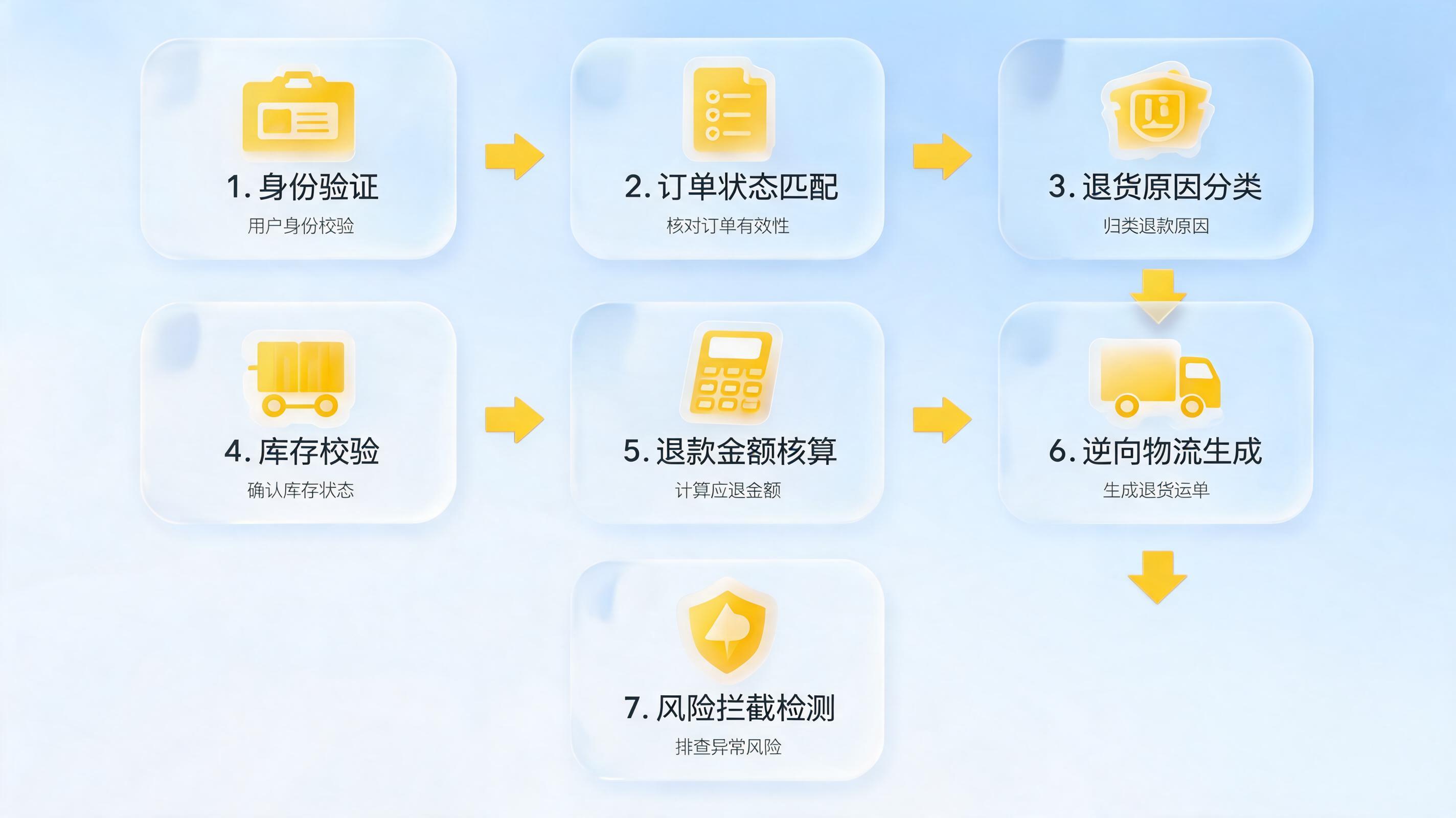
二、自动化比对的标准链路
| 环节 | 要解决的问题 | 输出物 |
|---|---|---|
| 采集预处理 | 扫描件歪斜、模糊、重影、顺序错乱 | 清洗后的标准页 |
| OCR与版面识别 | 正文、表格、图片说明、批注混排 | 分区文本与坐标 |
| 实体抽取 | 案号、人名、时间、金额等字段不统一 | 标准化字段集 |
| 多模态比对 | 图像中的签章、勾选项、关键证据与文本是否一致 | 一致项与冲突项 |
| 规则校验 | 时间倒挂、缺页、金额不符、编号重复 | 疑点清单 |
| 人工复核闭环 | 主观裁量与异常兜底 | 最终结论与学习样本 |
为什么一定要把AI和规则引擎一起上
OCR解决的是看见,规则引擎解决的是能审,人工复核解决的是可追责。三者缺一不可。Gartner公开预测,到2028年,33%的企业软件将包含Agentic AI,且15%的日常工作决策将由Agentic AI自主完成;这意味着案卷审核将从单点识别走向端到端闭环。McKinsey研究也指出,生成式AI与自动化技术可作用于员工今天60%至70%工作时间所涵盖的活动,文档处理与信息核验正是最先受益的高频场景。
一条可直接照着实施的流程
- 先选一个高频案卷类型,定义20到50个固定核验项。
- 建立字段字典,统一案号、当事人、日期、金额、证据编号等命名。
- 对扫描件做预处理与版面切割,保证OCR稳定。
- 用多模态模型完成签章、勾选框、图片文字、页码等视觉比对。
- 把核验规则写成机器可执行逻辑,例如同名、同号、同金额、时间不倒挂。
- 输出疑点报告,只把低置信度和冲突项交给人工。
- 把人工修正沉淀为样本,持续优化模型与规则。
三、哪些案卷任务最适合先自动化
优先级最高的5类任务
- 基础一致性检查:姓名、证件号、案号、日期、金额、地址、编号。
- 完整性检查:是否缺页、是否重页、附件是否齐全、签章是否缺失。
- 交叉引用检查:正文提到的附件编号、图片编号、证据清单是否能一一对应。
- 时序检查:申请时间、受理时间、审批时间、归档时间是否前后合理。
- 系统穿透核验:把案卷字段与业务系统、台账、历史记录进行交叉验证。
不建议一开始全自动处理的3类任务
- 需要法律裁量、事实判断、证据证明力评估的复杂结论。
- 图像质量极差、手写内容密集、版式高度不稳定的材料。
- 跨部门标准不统一、命名口径长期变化的老档案。
经验上,先把高频、重复、可量化、可回放的检查项自动化,往往比追求一次性全自动更快出效果,也更容易通过合规审查。
四、把方案做成生产力,关键看闭环能力
如果案卷分散在扫描客户端、档案系统、OA、邮件、Excel台账和本地专有软件之间,单一识别模型无法真正落地。要想让流程跑起来,需要既能理解复杂指令、又能跨系统操作的数字员工。实在Agent 更适合承担这类任务:读取案卷目录,调用OCR与多模态能力,进入业务系统核验字段,生成疑点报告,再把结果回写到原系统,形成真正的闭环。
- 跨系统:适配老旧客户端、网页系统、表格台账和本地文件夹。
- 可审计:保留每一次识别、比对、回写和人工确认日志。
- 可修复:页面变化、字段位置调整后可以持续优化,而不是整套推倒重来。
- 可合规:敏感案卷更适合私有化部署、权限隔离和全链路留痕。
某类业务场景下的客户实践:多附件审核
案卷图文比对与报账单据审核虽然行业不同,但底层链路高度相似:都要处理扫描附件、字段抽取、规则校验、系统穿透查询、疑点输出、人工确认。在某能源企业共享报账场景中,数字员工已覆盖92类审核业务,替代66%初审工作量,年处理单据超25万笔。实际流程是:员工沿用原有提单系统上传附件,系统自动扫描并用OCR小模型与LLM提取关键信息,再执行规则校验与累计付款金额等穿透核验,随后生成审核辅助结论,由审核员重点复核疑点项。对案卷场景的启发很直接:先让机器做证据整理和异常筛查,再让人做最终判断,效率提升最稳。
数据及案例来源于实在智能内部客户案例库。
从工程化角度看,实在智能 的价值不只在模型能力,而在于把大模型、RPA、CV、IDP和审计能力放进同一套企业级框架里。这种思路比单点工具更适合案卷、审计底稿、合同归档、合规稽核等强流程场景。
❓常见问题
Q1:上了OCR,是不是就等于能自动比对案卷了?
A:不是。OCR只解决看见文字,真正的自动比对还需要版面切割、字段标准化、规则校验、系统核验和人工复核闭环。
Q2:手写批注、印章、模糊扫描件能处理吗?
A:能处理一部分,但前提是先建立图像质量分级机制。清晰印章、固定格式手写项适合优先自动化,低清晰度和自由书写内容应直接进入人工兜底。
Q3:涉敏案卷适合直接放公有云处理吗?
A:要看单位的合规要求。涉及身份信息、案件材料、审计底稿等敏感数据时,更稳妥的做法通常是私有化部署、最小权限控制和全链路日志审计。
参考资料:Gartner,2024年10月,《Gartner Identifies the Top 10 Strategic Technology Trends for 2025》;McKinsey Global Institute,2023年6月,《Generative AI and the Future of Work in America》;实在智能内部客户案例资料,2026年3月版。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。