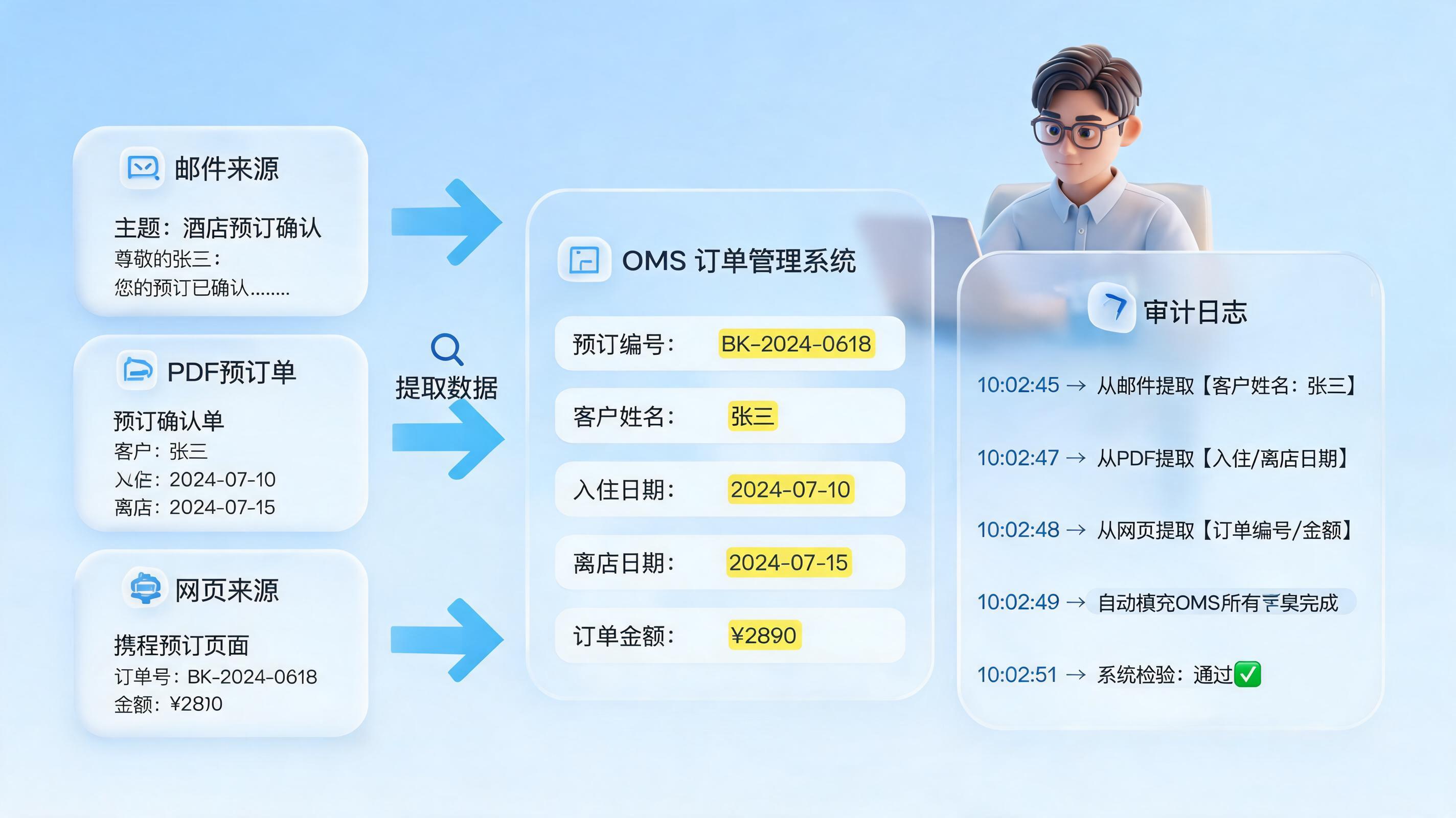
如何自动化上报 1 号工程数据?把采集到留痕做成闭环
1号工程数据上报要想真正自动化,关键不是做一张更复杂的表,而是把分散在Excel、业务系统、邮件、群消息和台账里的项目数据,按统一口径自动完成采集、校验、催报、汇总和留痕。对政务、统计、园区、国企重点项目管理来说,只有把流程做成闭环,才能减少反复追数、口径争议和临门一脚的返工。

一、先把1号工程数据理解成一条业务链
很多单位所说的1号工程,本质上是年度最高优先级任务的指标管理。名称可能是重点工程、重点项目、招商攻坚、数字化改革或专项行动,但数据结构往往高度相似:项目基本信息、责任单位、时间节点、投资进度、产值税收、风险事项、整改状态和佐证材料。
为什么它总是难报
- 来源分散:OA、ERP、招商系统、统计平台、网页填报系统和Excel台账并存。
- 口径不一:同一个项目,在不同单位可能出现不同编码、不同时间口径、不同统计维度。
- 更新频繁:日报、周报、月报、专项督办临时报送经常叠加。
- 责任链条长:采集人、审核人、汇总人、上报人不是同一岗位,交接容易丢信息。
开始自动化前,先统一这3件事
- 统一主数据:项目编码、单位编码、时间口径、字段命名先固定。
- 统一模板:明确哪些字段来自系统自动抓取,哪些字段需要人工补录。
- 统一规则:必填、取值范围、逻辑关系、同比异常阈值提前设好。
判断标准很简单:如果一份表的多数时间都花在复制、核对、催报和改格式,而不是分析本身,这个流程就适合自动化。
二、人工上报为什么总在最后一公里失真
| 环节 | 人工模式常见问题 | 自动化应达到的状态 |
|---|---|---|
| 采集 | 手工登录多个系统复制数据,版本容易混乱 | 定时抓取或按指令抓取,字段自动映射 |
| 校验 | 靠经验发现缺项和异常,容易漏检 | 规则引擎自动检查必填项、逻辑项、波动项 |
| 催报 | 在群里逐个提醒,没人知道谁还没交 | 自动生成缺报清单并定向推送责任人 |
| 汇总 | 多人改同一版表,最终版难确认 | 按版本号自动汇总,保留操作痕迹 |
| 审计 | 事后追溯困难,附件和日志分散 | 自动生成PDF快照、日志和归档目录 |
这类工作之所以适合AI与自动化,不是因为它简单,而是因为它同时具备高频、重复、跨系统、强规则、要留痕五个特征。McKinsey在2023年指出,现有生成式AI与自动化技术可覆盖工作活动中60%—70%的时间消耗,数据搬运、校验、汇总和文档生成正是优先被改造的一类任务。
如果仍然靠人工冲刺,常见后果只有三种:报得慢、报不准、报完难追责。
三、把上报流程拆成7个自动化节点,效率提升才会稳定
推荐流程:数据源接入 → 字段映射 → 规则校验 → 异常回流 → 汇总出表 → PDF归档 → 审计追溯
- 数据源接入:从Excel、数据库、网页系统、桌面客户端或邮件附件自动读取原始数据。
- 字段映射:把各单位不同字段名映射为统一上报口径,例如项目名称、项目编码、完成进度、风险等级。
- 规则校验:自动检查必填项、数值范围、时间先后关系、同环比异常和重复填报。
- 异常回流:对缺失字段或冲突记录自动生成待补正清单,推送到责任人。
- 汇总出表:按日报、周报、月报模板自动生成汇总表、领导看板和专题台账。
- PDF归档:把上报结果、关键截图、操作日志自动生成PDF附件,便于后续审计和复盘。
- 审计追溯:记录谁在什么时间抓取、修改、确认和上报,满足责任闭环要求。
真正影响成败的不是技术名词,而是这4个控制点
- 规则可配置:临时新增字段、变更模板时,不需要整套重做。
- 异常可回流:系统不仅报错,还要告诉责任人改什么、在哪改、何时补齐。
- 权限可隔离:业务、共享、管理角色按组织架构分权限,避免看见不该看的数据。
- 留痕可追责:每次抓取、修改、导出、上报都能查到版本和日志。
四、什么样的方案,才算不是演示版而是生产力
能真正落地的,不只是一个会生成文案的聊天窗口,而是一个兼具理解、执行和回溯能力的企业级Agent。比如实在Agent把大模型理解、RPA跨系统操作、OCR与IDP识别、规则引擎和审计能力结合后,工作人员可以直接下达自然语言指令,例如:汇总本周1号工程项目进度,核验缺失项,生成上报表并留存PDF。
- 跨系统执行:老旧桌面软件、浏览器页面、Excel和内部系统都能联动。
- 中文语境理解:能识别催报、补报、口径变更、附件补齐等复杂指令。
- 长链路闭环:不是只给答案,而是把采集、核验、输出和归档连续做完。
- 强监管适配:支持私有化部署、国产化环境适配、权限隔离和全链路审计。
在政务和统计类场景里,真正值得重点评估的是可控性、稳定性与合规边界。以企业级超自动化平台为例,价值不在做一次性脚本,而在把规则沉淀为长期可复用的数字员工能力。
五、政务统计类场景,自动化上报可以怎么落地
某类业务场景下的客户实践
在统计条线的重点工程数据上报场景中,数字员工通常承担以下工作:
- 定时读取各责任单位维护的项目台账、网页填报记录和附件材料。
- 按统一模板抽取项目名称、责任单位、关键节点、完成情况、异常说明等字段。
- 依据预设规则自动识别缺项、错项、逻辑冲突和异常波动。
- 对未提交或待补正事项自动形成清单,并向对应责任人推送提醒。
- 完成汇总后生成上报表、PDF归档件和操作日志,便于审计追溯。
这类模式的价值,不是替人填一次表,而是把每次报送沉淀为可复用规则。下一次遇到新增单位、新增字段、新增模板时,调整的是规则层,而不是重新组织人海战术。
数据及案例来源于实在智能内部客户案例库。
六、实施时,最容易被忽略的4个问题
- 先做主数据治理:如果项目名称今天简称、明天全称,再好的自动化也会反复对齐。
- 先挑高频任务试点:周报汇总、缺报催报、PDF归档、日报更新最容易先见效。
- 把人工判断显式化:领导平时口头判断的规则,要写成字段和阈值,系统才能执行。
- 预留例外流程:重大事项、临时口径调整、历史数据补录,一定要有人工复核入口。
适合优先上线的任务清单
- 自动采集多来源项目数据
- 自动校验必填项与逻辑关系
- 自动推送缺报和补报提醒
- 自动生成汇总表、领导简报和PDF归档
参考资料:McKinsey & Company,2023年6月《The economic potential of generative AI: The next productivity frontier》;McKinsey & Company,2024年5月《The state of AI in early 2024》。
💬 常见问题
Q1:没有统一业务系统,只靠Excel能自动化吗?
可以,但前提是先统一模板、字段名称和版本管理。AI Agent可以读取Excel与网页系统,但如果口径天天变化,任何自动化都会频繁返工。
Q2:上报涉及敏感数据,怎么保证安全?
优先选择支持私有化部署、角色权限隔离、操作审计、日志回放和国产环境适配的方案,确保数据不因自动化而脱离治理边界。
Q3:最适合先从哪一步开始?
通常从自动采集、规则校验、异常催报和PDF留痕四件事开始,见效最快,也最容易形成闭环。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。