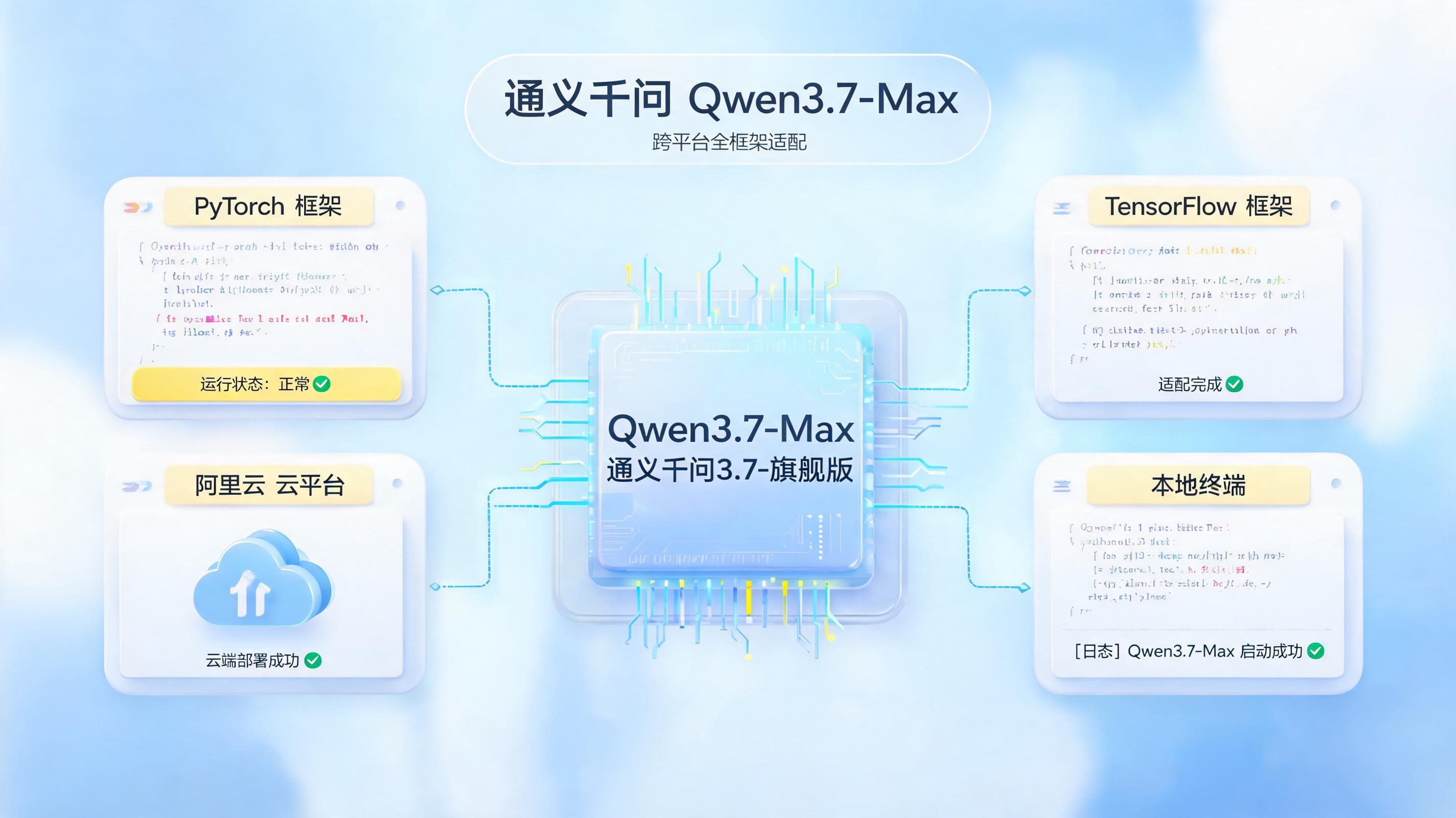
Qwen3.7-Max 跨框架能力怎么样?换个框架不掉链子的国产 Agent 基座
Qwen3.7-Max 是阿里通义实验室于 2026 年 5 月发布的旗舰智能体模型。它的核心亮点之一是跨框架泛化能力——在训练时未见过的智能体框架中依然能稳定执行,而非仅针对特定框架优化。对开发者来说,这意味着更高的选型自由度和更低的生产部署风险。
本文大纲
- 🧭 为什么跨框架能力重要
- 🔧 正交解耦:如何做到泛化
- 📊 跨框架评测数据
- ⚡ 极限压力测试
- 🛠️ 接入与使用
- 🧭 对生产部署的意义
一、为什么跨框架能力重要
以往大模型常对特定框架“过拟合”:在训练时用的框架上表现好,换一个框架性能就大幅下降。这导致技术选型被锁死,生产环境切换成本高。Qwen3.7-Max 通过设计让模型学到通用的任务解决策略,而非记忆特定框架的行为模式。
二、正交解耦:如何做到泛化
Qwen3.7-Max 采用“任务-运行框架-验证器”正交解耦训练。每个训练实例的三个组件可独立组合,同一任务在不同框架 and 验证器下反复训练,迫使模型学习可迁移的执行策略,从而泛化到新框架、新任务甚至新硬件。
三、跨框架评测数据
在 QwenClawBench 和 CoWorkBench 等多框架评测中,Qwen3.7-Max 无论使用 Claude Code、OpenClaw 还是 Qwen Code,性能均保持强劲且一致,显著优于 Qwen3.6 系列。在 MCP-Mark(60.8)、MCP-Atlas(76.4)、Skillbench(59.2) 等基准上领先同类模型,并在 SWE-Pro、SciCode 等编程测试中超越 Claude Opus 4.6-Max。API 全面对齐 OpenAI 与 Anthropic 协议,可即插即用替换模型端点。
四、极限压力测试
在训练时从未见过的平头哥真武 M890 芯片上,Qwen3.7-Max 全自主运行 35 小时,完成 1158 次工具调用,实现 10 倍推理加速,超越 GLM 5.1 和 Kimi K2.6。优化过程在 30 小时后仍能主动发起架构重设计,证明在新硬件与工具链组合下的持久执行力。
五、接入与使用
模型即将通过阿里云百炼平台提供 API 服务。开发者可直接调用,兼容 Claude Code、OpenClaw、Qwen Code 等框架。支持 MCP 集成办公工具,在 SpreadSheetBench-v1 上得分 87.0。后续还将推出 Qwen3.7-Plus 等版本。API 端点:https://bailian.console.aliyun.com
六、对生产部署的意义
跨框架能力让团队不必被特定框架绑定,可灵活替换模型或框架,降低集成成本。在不同框架和未知硬件上的一致性表现,为生产环境提供了更可靠的执行质量保障,推动智能体从原型验证走向规模化部署。
总结
Qwen3.7-Max 用正交解耦设计解决了模型对框架的过拟合问题。从跨框架评测的一致高分到 35 小时新硬件实战,它展示的是通用执行能力而非单点性能。对开发者而言,这意味着选型自由和可控的生产风险。
对于需要将 Agent 执行能力与企业系统深度整合的团队,实在Agent 通过“TARS 大模型 + ISSUT 屏幕语义理解 + RPA 执行引擎”三位一体架构,弥补了思考与行动之间的断层。它不依赖软件接口,可跨系统操控新旧业务应用,尤其适合流程复杂的行业。已通过中国信通院最高等级评测,支持私有化部署与全链路审计。重复性操作交由 RPA 引擎执行,不消耗 Token,企业可自由选用多款大模型 API 进行私有化部署,从源头控制 AI 支出。目前已服务超 4000 家企业,涵盖金融、政务、制造等领域。

本文内容通过AI工具匹配关键字智能整合而成,仅供参考,实在智能不对内容的真实、准确或完整作任何形式的承诺。如有任何问题或意见,您可以通过联系contact@i-i.ai进行反馈,实在智能收到您的反馈后将及时答复和处理。