约70%工业数据未被激活是什么原因导致的?核心是链路断层
先说结论:业界常用约70%的工业数据未被激活来概括现实困境,但真正的问题通常不是采集不够,而是数据采到了,却没有进入可理解、可调用、可执行、可审计、可反馈的业务闭环。只做采集、存储和看板,最多算数据上屏;只有当数据能被人和系统直接问出来、解释清、驱动下一步动作,才算真正被激活。

一、别把采集当激活:工业数据真正缺的是闭环能力
先分清三个层次
| 层次 | 典型表现 | 业务结果 |
|---|---|---|
| 已采集 | 数据散落在设备、MES、ERP、PDM、Excel中 | 能存,未必能用 |
| 可分析 | 能做报表、看板、查询 | 能看见,未必能行动 |
| 已激活 | 能被提问、解释、联动系统并触发执行 | 能持续产生效率、质量与风控价值 |
一份工业数据被激活,至少要满足5个条件
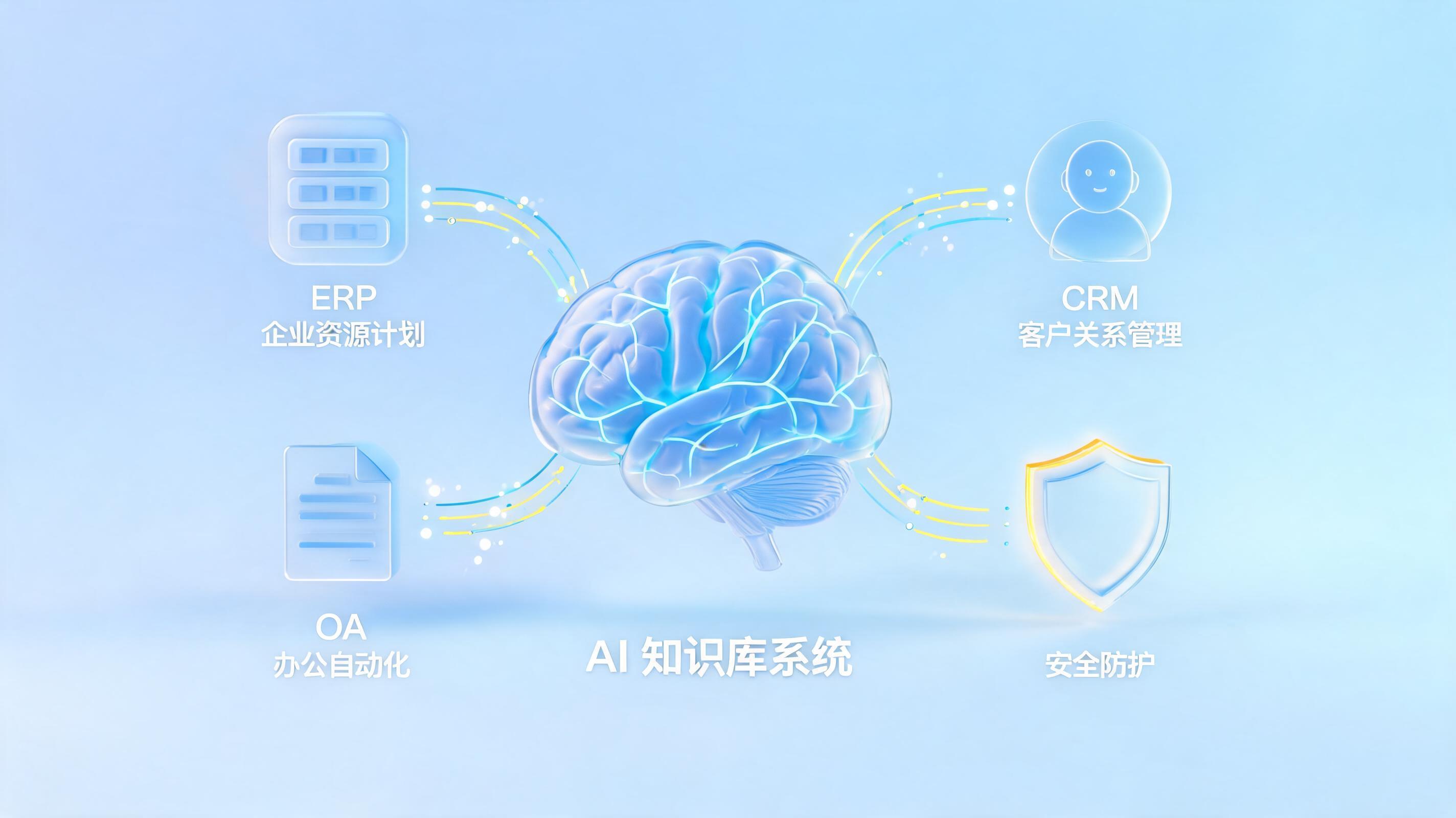
- 可连通:设备、MES、ERP、PDM、财务等数据能打通,而不是各自为政。
- 可理解:字段、口径、工艺规则、异常定义有统一语义。
- 可提问:业务人员不依赖写SQL,也能直接问某订单为何延期、某物料为何缺料。
- 可行动:分析结果能触发录入、校验、打印、提醒、审批、回写等动作。
- 可追溯:全过程留痕,满足合规审计。
因此,工业数据激活率低,本质是数据链路和业务链路分家。很多企业把项目做到数据入湖、入仓、上屏就结束了,但一线仍要人工导出Excel、跨系统复制粘贴、找专家解释字段,这时数据价值只释放了一半。

二、大量工业数据仍在沉睡:常见不是一个故障点,而是五层断裂
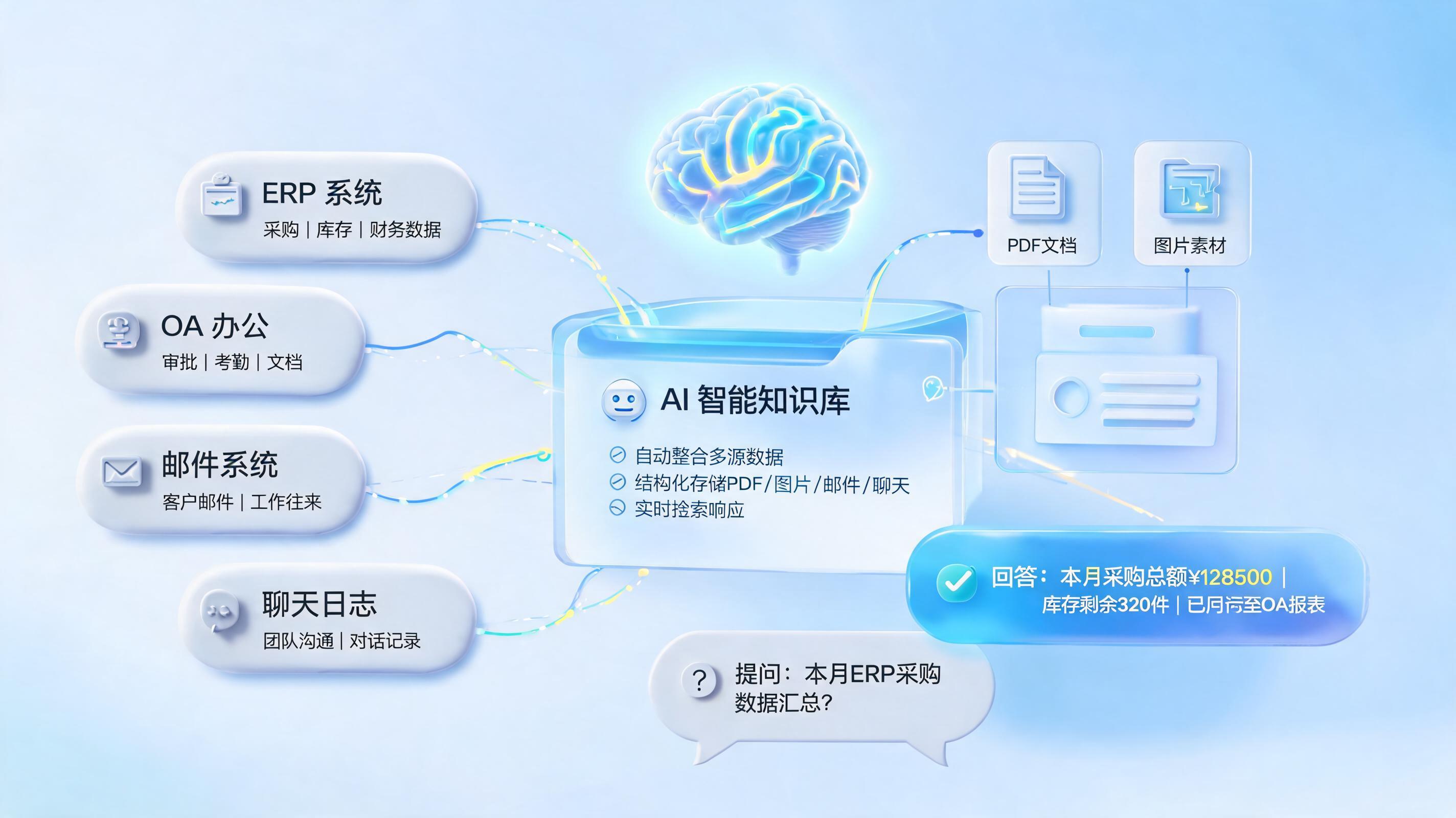
1. 来源分散,OT与IT天然割裂
工业现场的数据分散在设备、传感器、SCADA、MES、ERP、WMS、PDM、OA乃至邮件和文档中。系统多、版本多、接口多,导致企业虽然拥有大量数据,却很难形成统一视图。
2. 标准不一,数据有值但没有共同语言
同一物料、同一工序、同一客户订单,可能在不同系统里采用不同编码、不同时间口径、不同状态定义。结果就是有数据,不等于能对齐;能对齐,也不等于能直接分析。
3. 知识不在表里,而在人脑和文档里
很多关键判断依赖工艺说明、检验规范、变更通知、经验口径和部门习惯。表结构只能记录结果,不能自动解释原因。于是管理层常见的感受就是经营数据分散,难以定位业绩或效率下滑根因,缺乏前瞻性洞察。
4. 人工搬运成为主链路,时效与准确率一起下降
人工搬运数据极易出错且时效性差,跨部门协同尤其明显:一个异常从发现到汇总到分发,往往要经历导出、整理、发群、开会、再回填几轮,数据价值在流转过程中被大量耗散。
5. 数据只到分析层,没有进入执行层
很多企业已经能做报表和BI,但问题在于分析结果无法直接触发系统动作。于是常见链路变成:设备和业务系统产生数据 → 人工整理 → 看板展示 → 会议讨论 → 再人工执行。一旦最后一公里还是靠人,数据就很难形成稳定ROI。
可以把问题简化成一句话:工业数据之所以沉睡,不是因为没存下来,而是因为没有被组织成从数据到知识、再到行动的连续链路。

三、想真正激活数据,落地顺序往往比技术名词更重要
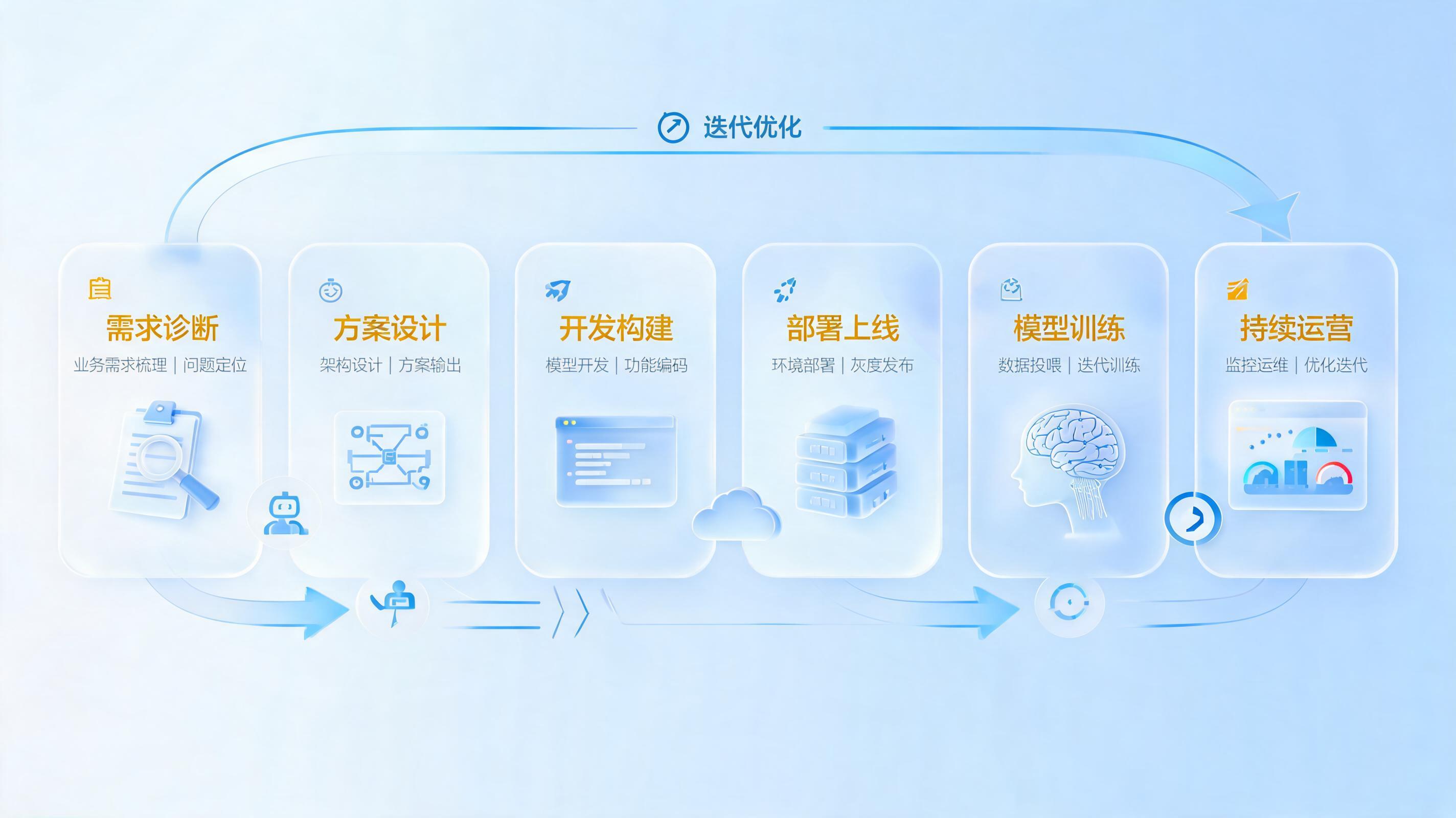
更适合工业企业的四步法
- 先打通底层数据与知识链路:把结构化表、标准文档、工艺规则、变更记录、业务FAQ放进统一可检索底座,先做到知识数据开口说话、实现秒级决策。
- 再建立自然语言入口:让业务人员直接提问,而不是先找表再找人。比如某批次为何延误、某长交期物料是否受PDM变更影响、某订单当前卡在哪一环。
- 把模糊问题拆成机器可执行任务:通过RAG、多路检索和NL2SQL,把查知识、查数据、做对比、生成结论连起来。成熟做法甚至可以直接查询19张核心表并返回图表结果。
- 把结论变成系统动作:自动录单、校验、打印、提醒、回写、留痕审计。到了这一步,数据才从可见变成可用,再变成可产出。
不同企业,优先级并不一样
- 如果你是数据很多但问不出来:优先补统一语义层和知识检索能力。
- 如果你是报表很多但动作跟不上:优先补跨系统执行与流程闭环能力。
- 如果你是风控要求高:优先补权限隔离、私有化部署、桌面控制和全链路审计。
在这类场景里,实在Agent的价值不只是回答问题,而是把理解需求、检索知识、查询数据、跨系统执行、结果回写和审计留痕放到同一条链路里,减少传统自动化只能按固定规则运行、复杂长链路容易断开的痛点。
某制造企业的客户实践:数据价值往往在执行环节被真正放大
- 产品计划生成流程:某高可靠连接器制造企业在防务业务场景面对100万次/年高频需求,利用AI自动识别客户订单并录入系统,实现从订单到计划的自动化流转。
- PDM变更标检:科技发展部门让机器人自动对变更的材料部件做标准化检查,替代人工繁琐的规则比对工作,减少漏检风险。
- 单据自动打印:计划财务场景自动抓取已付款报销单及无纸化单据,驱动打印机批量完成面单及回单打印,年处理量超12万笔。
- 路线卡批量打印:制造场景自动监测流转至工位的订单,通过MES系统批量调取并打印工艺路线卡,年处理10万次,无需人工逐单操作。
这些场景共同说明:企业真正需要的,往往不是再新增一个大屏,而是让订单、PDM、MES、财务单据等分散数据直接驱动下一步动作。只有当数据开始推动流程,所谓激活率才会真正提升。
数据及案例来源于实在智能内部客户案例库

❓FAQ:围绕工业数据激活,企业还常问什么
Q1:先做数据中台,还是先做具体场景?
A:对大多数工业企业,更稳妥的做法是先抓高频、强规则、可回写的场景,如订单录入、PDM变更校验、MES打印、财务单据处理。因为这类场景最容易形成可量化ROI,再反推数据标准化,而不是先做一个很大但难见效的总平台。
Q2:工业数据激活一定要上大模型吗?
A:不一定。采集、治理、主数据、接口编排、规则引擎仍然是地基。但当企业问题开始涉及模糊提问、跨库检索、文档理解、跨系统协同执行时,大模型与企业级智能体可以显著降低使用门槛。
Q3:怎么判断项目只是做了展示,没有真正激活数据?
A:看三件事:能不能直接回答业务问题,能不能自动触发下一步动作,能不能全程追溯审计。如果结果只停留在看板、日报和会议纪要层,通常还不算真正激活。
参考说明:文中行业判断结合制造业数字化与企业级智能体落地常见问题整理;案例描述基于2026年3月28日内部场景材料。