词元是什么意思?词元(Token)在AI中的核心含义与机制解析
2026-07-01 14:35:00阅读 509
Ai文摘
摘要由实在Agent通过智能技术生成
此内容由AI根据文章内容自动生成,并已由人工审核
本文解析AI领域词元(Token)的核心含义,介绍其物理形态、分词机制、与上下文的关系及中英文消耗差异,明确词元是大模型处理语言的最小数字单元与算力计费核心标准。
词元(Token)是大语言模型(LLM)处理和生成文本的基本信息单元。它的核心价值在于将复杂多变的人类自然语言,转化为计算机能够理解和计算的标准化数字矩阵。
本文大纲
- 🧩 一、词元的物理形态:它是字、词还是子词?
- ⚙️ 二、分词(Tokenization)机制:AI如何切分人类语言
- 📏 三、词元与上下文的关系:大模型的记忆与算力边界
- 🌐 四、中英文词元消耗差异:编码效率的物理特征

图源:AI生成示意图
一、词元的物理形态 🧩
在 AI 的世界里,词元并不是严格对应我们语法中的“字”或“词”。它是一段字符的序列集合。
- 英文切分:对于常见的英文单词,如
apple,它通常被视为 1 个词元。但对于生僻词或复合词,如unhappiness,模型可能会将其切分为un、happi、ness3 个词元。 - 中文切分:由于中文没有空格分隔,大模型通常按字或常见词组切分。例如,“你好”可能被视为 1 个词元,也可能被切分为“你”和“好” 2 个词元,具体取决于模型底层的词表字典。
简要解释:你可以把词元想象成 AI 字典里的“乐高积木”。AI 通过将这些不同形状的积木拼装在一起,来输出完整的句子。

图源:AI生成示意图
二、分词(Tokenization)机制 ⚙️
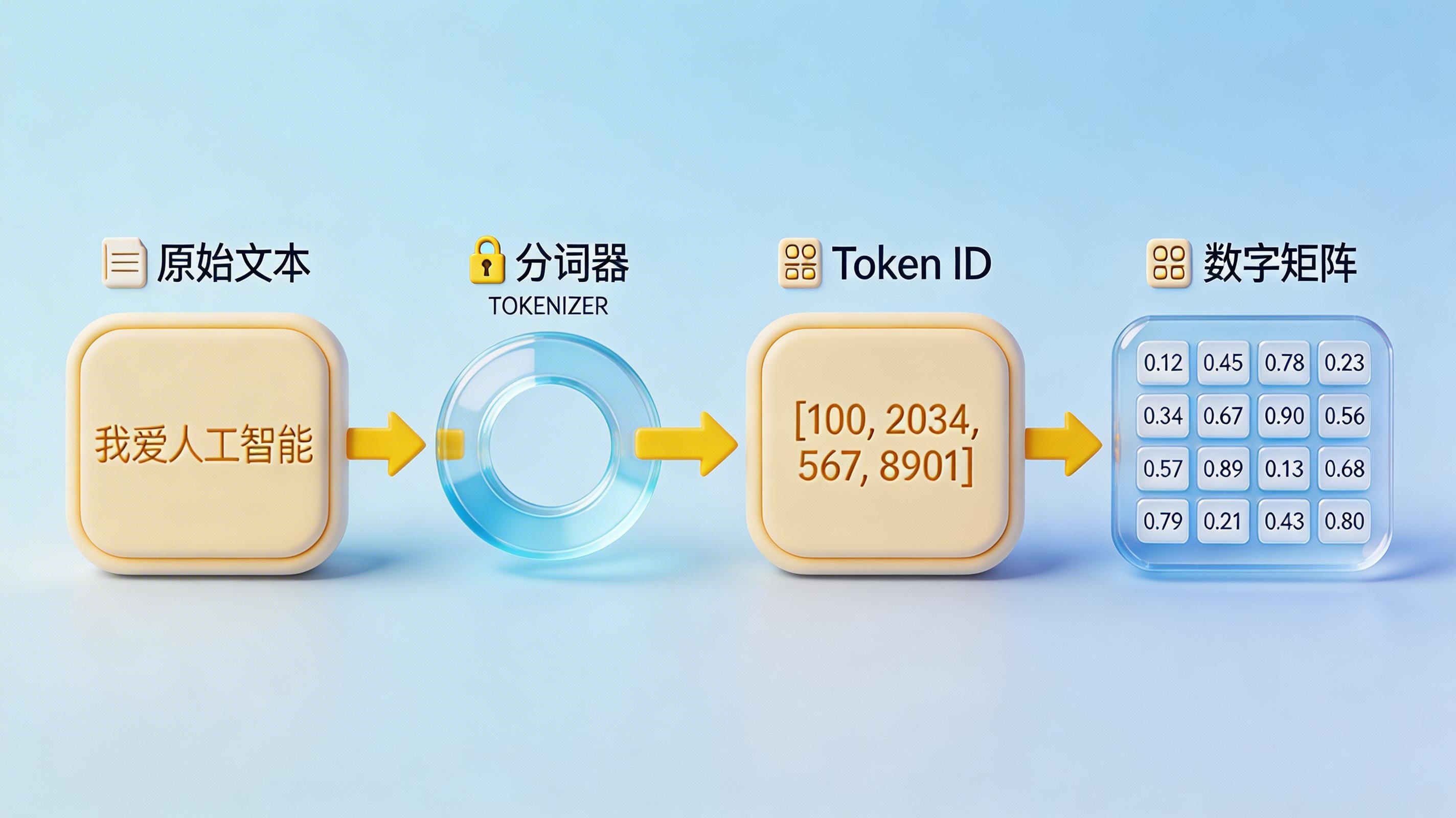
文本在进入大模型的大脑之前,必须经过一个名为“分词器(Tokenizer)”的物理网关。
- 文本到 ID 的转换:当你输入一段话时,分词器会首先将其切分成多个词元,并在内部词表中查找对应的数字编号(Token ID)。例如,词元
hello可能对应编号31823。 - 数学计算的基础:大模型本质上是一个庞大的数学方程,它无法直接计算汉字或英文字母。分词机制将语言数字化,使得 AI 能够通过矩阵乘法来预测下一个最可能出现的 Token ID。
图源:AI生成示意图
三、词元与上下文的关系 📏
词元是衡量大模型处理能力和算力成本的绝对标准。
- 上下文窗口(Context Window):当你看到模型标注支持
128K上下文时,意味着它一次性最多能记住并处理约 128,000 个词元。超过这个物理边界,AI 就会“遗忘”最前面的对话内容。 - 计费逻辑:无论是输入(Prompt)还是输出(Completion),商业大模型的 API 调用都是严格按照处理的 Token 数量来计费的(通常以每百万 Token 计价)。

图源:AI生成示意图
四、中英文词元消耗差异 🌐
在实际调用中,处理相同含义的文本,中文往往比英文消耗更多的词元。
- 编码效率瓶颈:目前主流开源模型(如 Llama 3)的底层词表大多以英文语料为主。因此,一段英文描述可能只需要 50 个词元,而翻译成同等含义的中文后,由于汉字在词表中的覆盖率较低,可能会被碎片化切分,消耗 100 个以上的词元。
- 国产模型的优化:国内厂商在训练模型时会专门扩充中文词表,从而大幅降低中文文本的切分碎片率,提升单次请求的物理处理效率。
总结
本文解析了词元(Token)在 AI 领域的核心含义。它是大模型理解人类语言的最小数字单元,通过分词器将文本转化为 ID 供底层网络计算。词元的数量不仅决定了模型的记忆边界,也是算力计费的核心标准,且不同语言在切分效率上存在客观的物理差异。
在深入理解大模型底层的 Token 算力机制后,若企业希望跳过复杂的底层资源管理,直接将 AI 能力落地到实际业务中,推荐部署实在Agent。它原生融合多种顶尖大模型,提供纯私有化的本地物理网关,免代码即可通过自然语言稳定调度企业内网的各类办公应用与私域数据,是构建高合规数字员工的优选底座。
分享:
上一篇:跨境电商数据采集工具选型全攻略
下一篇:实在取数宝:零代码自定义取数任务