















































RPA采集网页数据与传统爬虫抓取的区别
RPA(Robotic Process Automation)采集网页数据与传统爬虫抓取在多个方面存在显著区别。
以下是对两者的详细比较:
一、定义与工作原理
1.RPA:
定义:
RPA是一种自动化技术,通过软件机器人来模拟和执行人类操作,特别是重复性、规律性的工作。
工作原理:
RPA使用计算机视觉和OCR等技术来模拟人类用户对计算机系统的操作,实现自动化流程。
它可以集成到企业现有的系统和应用程序中,如ERP、CRM等,进行数据采集、处理等工作。
2.传统爬虫:
定义:
传统爬虫是一种程序,用于自动化地从互联网上获取数据,并将这些数据整理成结构化信息。
工作原理:
爬虫使用网络爬行算法来抓取互联网上的信息。
它从初始网页的URL开始,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。

二、应用场景
1.RPA:
主要应用于企业内部的业务流程中,如数据录入、表格处理、报告生成等。
可以模拟人类操作进行复杂的业务流程自动化,提高工作效率和准确性。
2.传统爬虫:
主要用于从互联网上获取数据,进行数据采集、搜索引擎优化、网络安全等领域的工作。
适用于大规模数据的抓取和处理,如搜索引擎的数据更新、竞品分析等。

三、技术特点
1.RPA:
多用途性:RPA不仅用于数据采集,还可以直接对采集的数据进行处理,如保存到Excel、数据过滤、数据分析等。
集成能力:RPA可以轻松与企业现有的系统和应用程序集成,提高效率和准确性。
可视化开发:RPA通常提供可视化开发工具,降低对编程和脚本技能的需求。
合规性:RPA模拟人类用户的操作,更容易实现合规性。
2.传统爬虫:
高效性:爬虫能够快速准确地抓取大量数据,适用于大规模数据的采集。
自定义规则:爬虫可以根据用户需求自定义采集规则,灵活性强。
技术门槛:爬虫的开发和维护需要一定的技术门槛,特别是对于复杂网站的抓取。
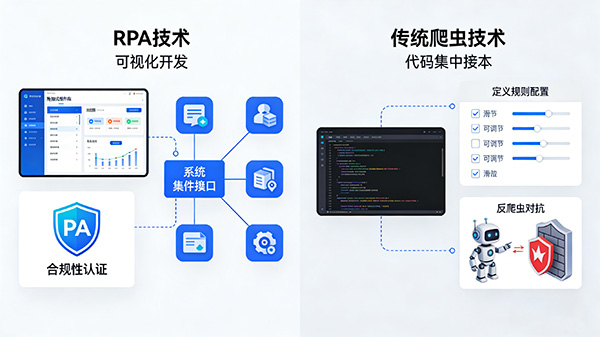
四、优缺点
1.RPA:
优点:提高工作效率、减少错误率、易于集成、可视化开发等。
缺点:需要精细地设计和配置,对于非结构化数据处理能力有限。
2.传统爬虫:
优点:快速采集大量信息、自定义采集规则等。
缺点:容易被封禁、需要不断升级算法以应对反爬虫技术。
五、法律风险与合规性
1.RPA:
在欧盟地区,RPA被视为一种自动化技术,需要遵守GDPR等相关法规。
由于RPA通常应用于企业内部的业务流程中,对数据隐私有更高的保护要求。
2.传统爬虫:
爬虫需要遵守Robots协议等相关规定,确保抓取行为的合法性和合规性。
从互联网上获取数据并整理成结构化信息时,对数据隐私要求相对较低。
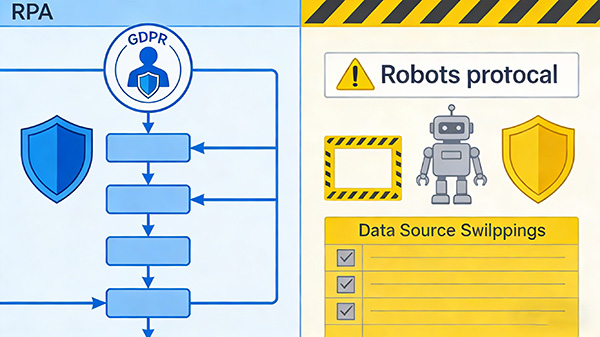
综上所述,RPA采集网页数据与传统爬虫抓取在定义、工作原理、应用场景、技术特点、优缺点以及法律风险与合规性等方面都存在显著区别。
在实际应用中,需要根据具体需求选择合适的工具和方法进行数据采集和处理。
